





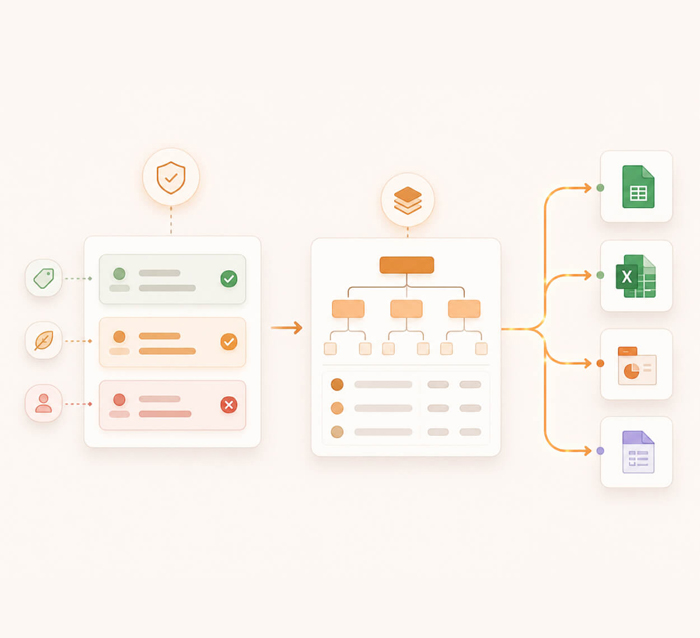
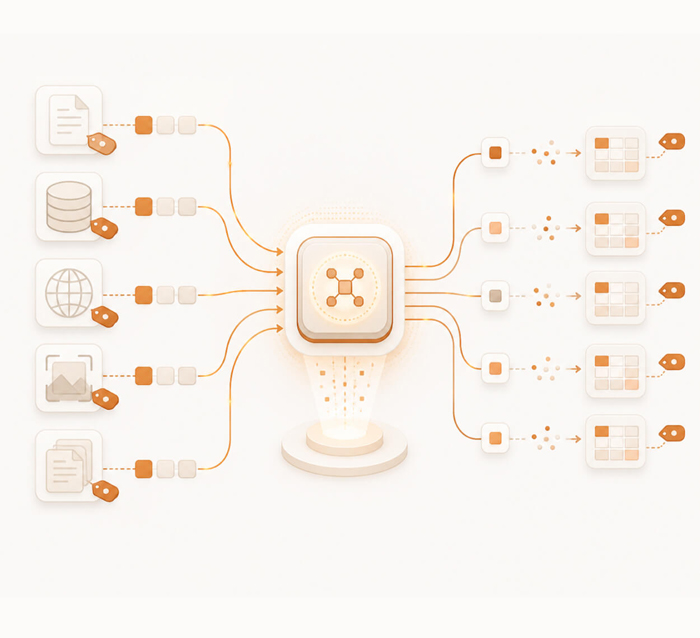

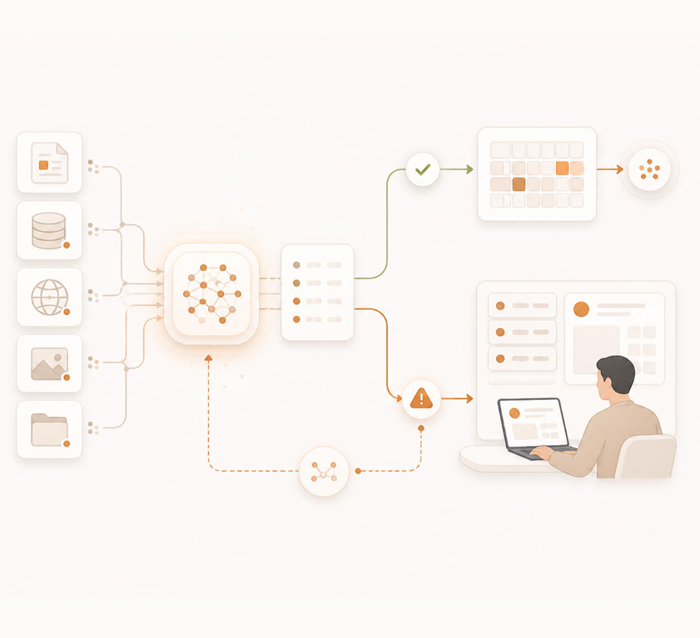
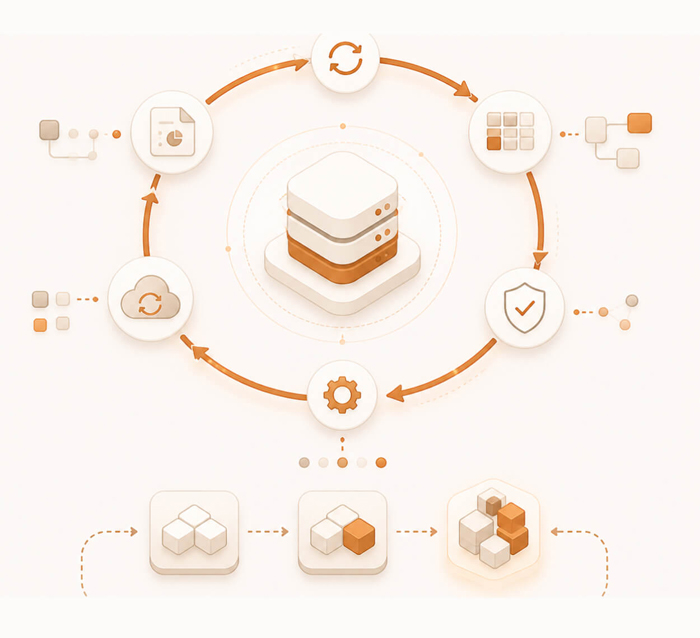









Environmental, social, and governance data collection, with cross-pillar verification, metric calculation, and multi-framework mapping.

8000+
Companies Covered800,000+
Data Points Processed100%
Source-Documented Data- Service ESG Research Services Environmental Research Services Social Research Services Corporate Governance Data Research
- Platform Client's Proprietary ESG Rating Platform
- Industry ESG & Sustainability Consulting

Labeled and validated over 10,000 high-resolution drone images monthly using QuPath to train an AI-powered livestock detection model, delivering 95%+ annotation accuracy.
10K+
Images Annotated Monthly95%+
Labeling Accuracy- Service Image Annotation
- Platform QuPath
- Industry Agriculture (AgriTech)

Delivering audit-ready, source-documented datasets for a North American investment consulting firm's proprietary climate risk platform.
6000+
CompaniesCovered
250k+
Environmental Data Points Processed100%
Source-DocumentedData
- Service Environmental Research Services ESG Research Services
- Platform Client's Proprietary Climate Risk Assessment Platform
- Industry Investment & Financial Consulting

Helping a Water Technology Company Boost Its Marketing and Sales Effort Through Salseforce Data Cleansing and Account Profiling
39%
Improved Email Delivery Rate25%
Increase in Click Through Rate52%
Boost in Sales With Clean and Accurate Data- Service Salesforce Data Entry Custom List Building Salesforce Data Management Web Research
- Platform Salesforce Apollo LinkedIn ZoomInfo
- Industry Environmental Technolgy

Helping a global provider of magnetic sunglasses to improve its declining sales with email list cleanup services
60%
Boost In Response Rate48%
Budget Savings By Reducing Wastage40%
Increment in Conversion Rate- Service Email List Cleanup Data Cleansing and Verification
- Platform Neverbounce Apollo ZoomInfo
- Industry eCommerce
Processed and validated 100,000+ monthly vehicle valuation enquiries through data cleansing, standardization, and integrated quality checks, delivering CRM-ready outputs within 24-hour turnaround.
99.98%
Data Accuracy5K
Records per Day- Service Data Processing Data Standardization
- Platform Client’s Proprietary Valuation Tool
- Industry Automotive

Processed and validated over 10,000 multi-format invoices monthly (printed, scanned, and handwritten), ensuring seamless integration into the client's proprietary AP system.
99.95%+
Data Accuracy45%
Faster Invoice Processing40%
Operational Cost Savings- Service Invoice Processing
- Platform Client's AP Solution
- Industry Logistics









