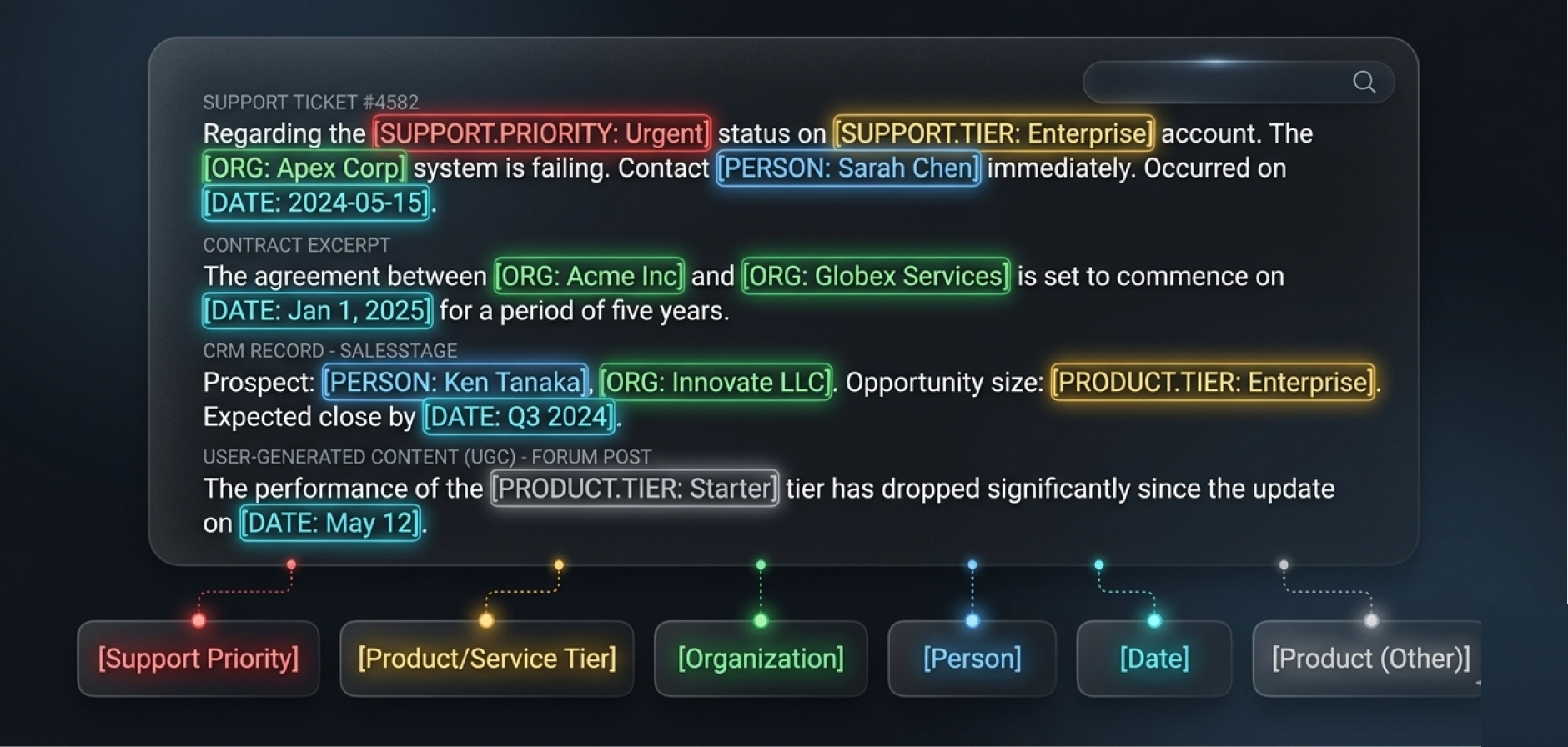
Standard NER annotation fails when entity types are ambiguous, nested, or domain-specific. We handle standard entity types and custom entity taxonomies specific to your model's requirements, with nested entity support and entity linking for knowledge graph construction.
- Standard NER annotation: persons, organizations, locations, dates, products
- Custom entity types labeling: medical conditions, drug names, legal clauses, financial instruments
- Nested and overlapping entity annotation with disambiguation
- Entity linking to external knowledge bases
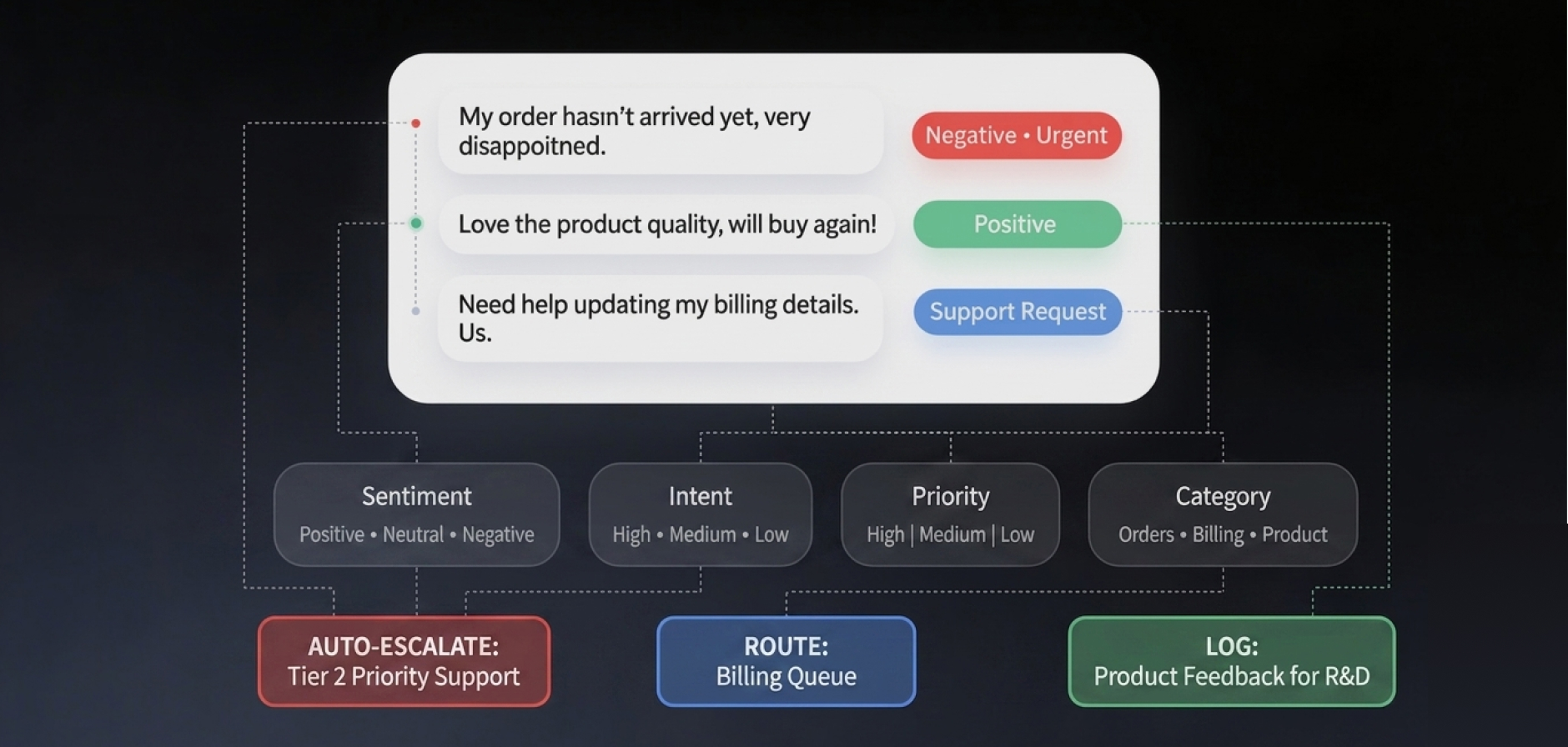
Binary positive/negative sentiment labels are insufficient for models that need to understand the emotional texture of customer feedback or support interactions. Our text annotation company delivers sentiment annotation for machine learning applications with aspect-level granularity.
- Aspect-level sentiment annotation (positive, negative, neutral, mixed) for specific entities or topics within text
- Emotion classification (anger, fear, joy, sadness) across expanded taxonomies
- Opinion mining annotation (Opinion holder, opinion target, and stance annotation) for argument-level analysis
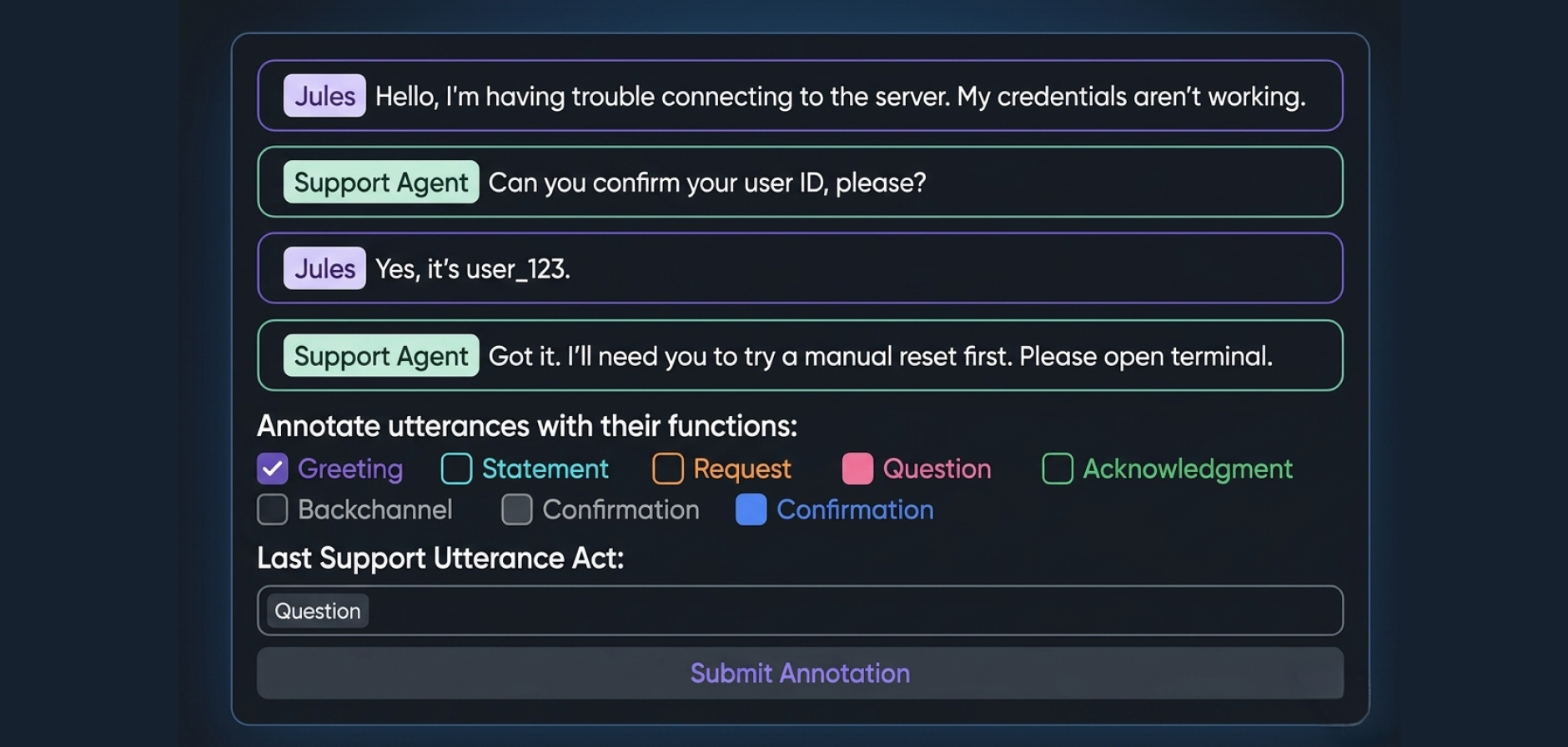
When intent labels are inconsistent or when dialogue datasets lack proper turn-level annotation, chatbots and conversation AI tools misfire on common inputs and cannot generalize across paraphrased variations. Our annotators are trained on your specific intent taxonomy and label intent/entity pairs to ensure consistency across high-volume datasets.
- Intent classification for chatbot and virtual assistant training
- Entity/slot annotation within conversational turns
- Multi-turn dialogue annotation with context tracking
- Dialogue act and speech act classification
- RLHF preference annotation for LLM fine-tuning
Our text data annotation service team is fully briefed on your label definitions and tested with a pilot on gold-standard samples. The labeled text datasets are monitored for IAA compliance throughout the process. This ensures that they understand the full label taxonomy and can apply it consistently across multi-class and multi-label text classification tasks.
- Binary, multi-class, and multi-label classification at the document, paragraph, and sentence level
- Hierarchical and flat taxonomy annotation
- News, legal, medical, financial, and e-commerce document tagging
- Topic modeling annotation and cluster labeling
- Continuous IAA tracking and conflict resolution
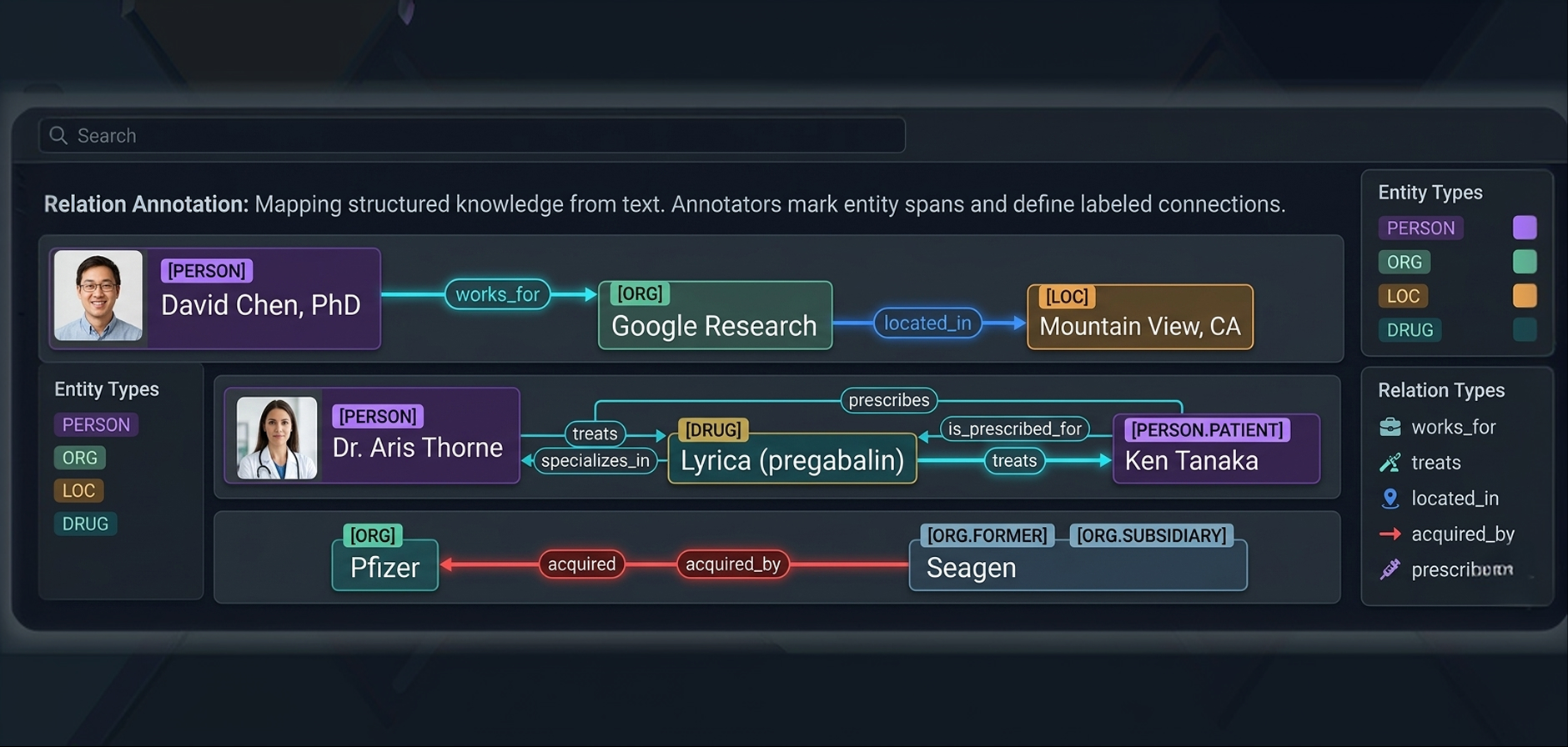
Relation extraction annotation (labeling explicit and implied semantic relationships between entities in complex text) is a very ambiguous task. We employ domain specialists for knowledge graph construction, semantic role labeling, event extraction, and causal relation tagging.
- Semantic annotation: agents, patients, locations, instruments
- Relation extraction: causal, temporal, part-of, and custom relation types
- Event extraction and event argument annotation
- Coreference resolution: pronoun and noun phrase co-reference chains
- Knowledge graph construction annotation
Our text annotation company operates in alignment with your model’s behavior objectives and quality goals. We train the team to recognize the subtle quality distinctions that determine whether RLHF training improves or degrades model performance, particularly for the use case you are building.
- Instruction tuning dataset creation for LLM fine-tuning
- RLHF preference ranking pairs for reward model training
- Supervised fine-tuning (SFT) dataset annotation
- Constitutional AI and alignment annotation
- LLM output evaluation: helpfulness, harmlessness, and honesty scoring
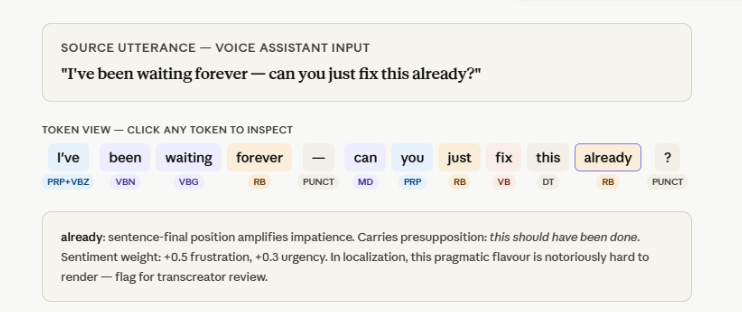
We go beyond simple translation when annotating data for specialized AI Models, such as voice assistants, conversational AI, localized chatbots, and such text-to-speech models. Our linguistic experts provide deep-dive analysis of grammar, dialect, and sentiment to ensure your AI communicates with natural, human-level fluency across.
- Semantic & syntactic analysis to identify parts of speech, sentence structure, and how words relate to each other
- Localization & transcreation so AI responses sound like native text with similar meaning as the original
- Phonetic & morphological transcription using the International Phonetic Alphabet (IPA)
- Sentiment & Intent Tuning: sarcasm, frustration, urgency, and the underlying goal of the speaker
- Natural Language Generation (NLG) evaluation for fluency, coherence, and hallucination
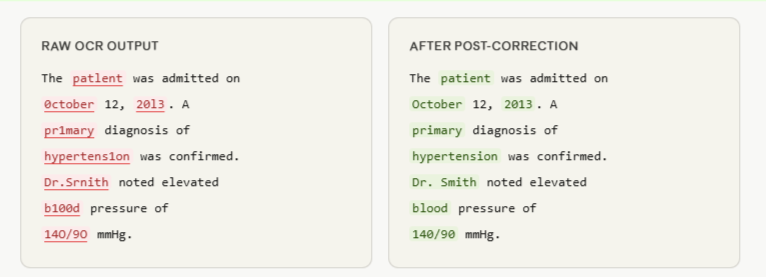
Optical character recognition output from scanned documents can contain character-level errors, introducing systematic noise into the training data that degrades model precision. We correct OCR output at the character, word, and sentence level, applying domain-specific vocabulary and context-aware correction for legal, medical, financial, and historical text.
- Domain dictionaries created and maintained for medical terminology, legal vocabulary, and financial instruments
- Form and table structure annotation from scanned documents and multi-page PDFs
- Historical document transcription, normalization, and character-set correction
- Integrated pipeline: OCR post-correction followed immediately by downstream NLP annotation