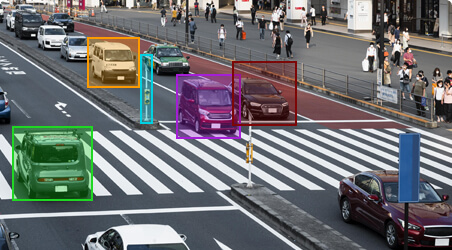
Loose boxes, inconsistent tightness, and dead space around objects are the fastest way to degrade your object detection model’s IoU scores. Our annotators follow documented tightness standards with attribute-level tagging (occluded, truncated, difficult), so your model trains on edge-aware data.
- Tight-fit bounding boxes with consistent margin standards across annotators
- Occlusion, truncation, and overlap tagging for robust object detection (YOLO, SSD, Faster R-CNN)
- 3D cuboid annotation for depth-aware perception in robotics, autonomous vehicles, and AR/VR
Pixel-level classification fails when annotators are inconsistent at class boundaries — especially where road meets sidewalk, where tumor meets healthy tissue, or where crop meets soil. Our segmentation workflow uses AI-generated masks, refined by annotators trained on your boundary definitions.
- Full-scene pixel-level classification with consistent class palettes across datasets
- AI-assisted mask generation via SAM-based pre-labeling, refined by trained annotators
- Panoptic segmentation support: combined stuff + thing labels in COCO panoptic format
The real difficulty with polygon annotation is vertex density: too few vertices miss contours, too many slow throughput and introduce noise. Our annotators follow adaptive vertex density guidelines calibrated to object curvature, not arbitrary point counts. This matters when you need AI model training data to detect road signs at varied angles, building footprints in satellite imagery, or irregular defects in manufacturing.
- Multi-point polygon tracing with vertex-level precision on irregular object boundaries
- Nested and multi-region support for objects with holes or internal structures
- Export-ready formats: COCO polygons, GeoJSON for geospatial, and custom schemas
Keypoint schemas vary dramatically across use cases — COCO 17-point human pose, 68-point facial landmarks, custom hand-joint models. Annotators who are not trained on your specific schema produce inconsistent joint placements that cascade into pose estimation errors. Our teams are calibrated on your exact keypoint definitions, with visibility flags (visible, occluded, out-of-frame) enforced per joint.
- Custom keypoint schemas: body pose (COCO 17-point), facial landmarks (68/98-point), hand tracking
- Visibility flags: visible, occluded, and out-of-frame markers per point
- Applications: sports analytics, physical therapy AI, gesture-controlled interfaces, driver monitoring
When your model needs to count, track, or differentiate individual objects of the same class — cells in a pathology slide, cars in a lot, products on a shelf — overlapping masks and missed instances compound into production failures. Our annotators handle heavy occlusion through layered masking with annotator-defined occlusion flags.
- Per-instance mask generation with unique IDs for each object occurrence
- Cross-frame instance consistency for video-derived image datasets
- Dense scene support: warehouse inventory, crowd analysis, cell counting in pathology
Lane markings, power lines, pipelines, and conveyor boundaries require ordered vertex sequencing with directional awareness. Misordered vertices break downstream HD map generation and flow detection. Our annotators follow directional annotation protocols with spline-based smoothing for curved structures.
- Lane marking and road boundary annotation for HD map creation and ADAS training
- Utility and pipeline tracing for infrastructure inspection and GIS mapping
- Directional polylines with consistent start/end conventions
Safety-critical applications in autonomous transport, robotics, and industrial automation demand spatially accurate 3D labels. We annotate LiDAR point clouds with 3D cuboids, semantic labels, and temporal tracking across frames.
- 3D bounding cuboids with orientation, heading, and velocity attributes
- Semantic point-level labeling: ground, vegetation, vehicle, pedestrian, infrastructure
- Camera-LiDAR alignment: synchronized 2D image annotation and 3D point cloud annotation
- Temporal tracking: consistent object IDs across sequential scans
We verify and correct machine-extracted text from documents, signage, labels, and receipts, ensuring that your document understanding and text detection models are trained on clean ground truth. This is critical for invoices, IDs, and medical documents, where a single misread can have severe downstream consequences.
- Character-level validation of OCR engine outputs across document types
- Bounding box alignment correction for text detection AI model training
- Multilingual OCR support: Latin, CJK, Arabic, Devanagari scripts