




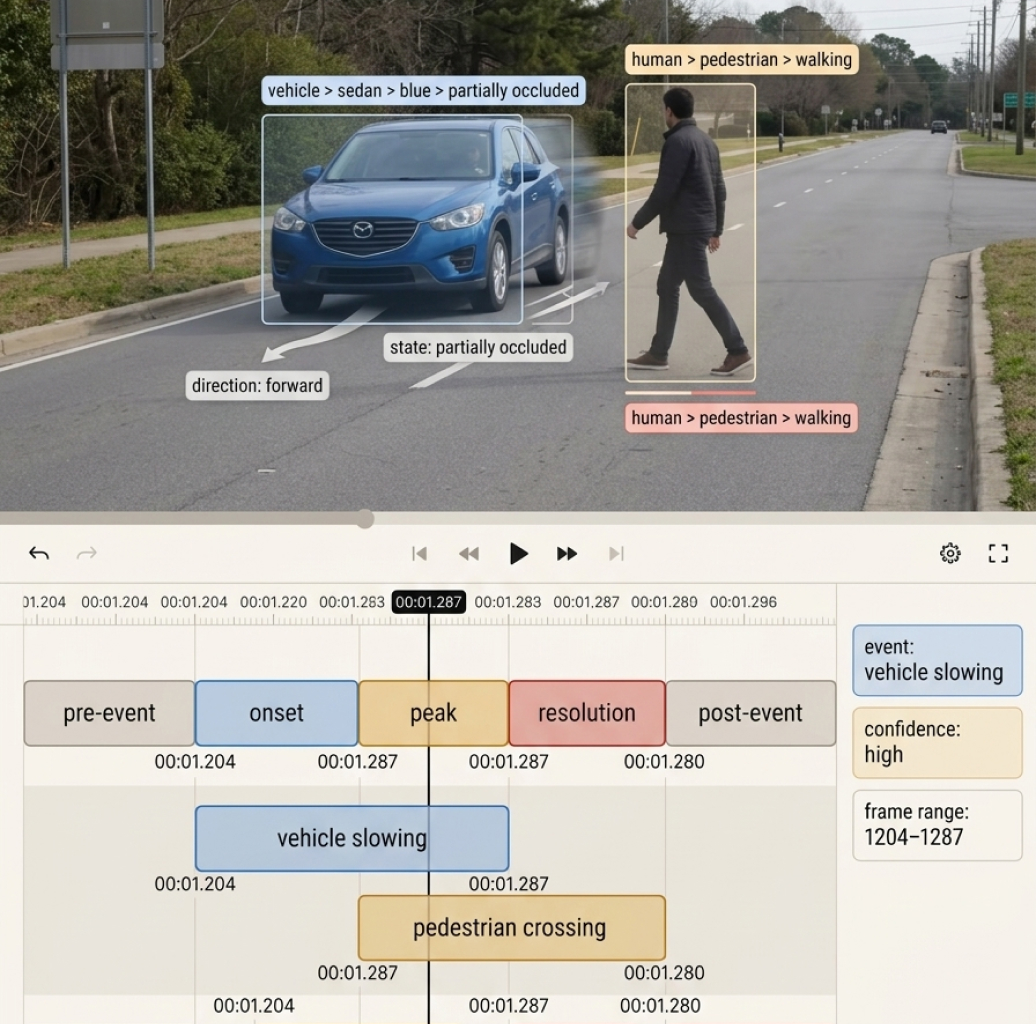

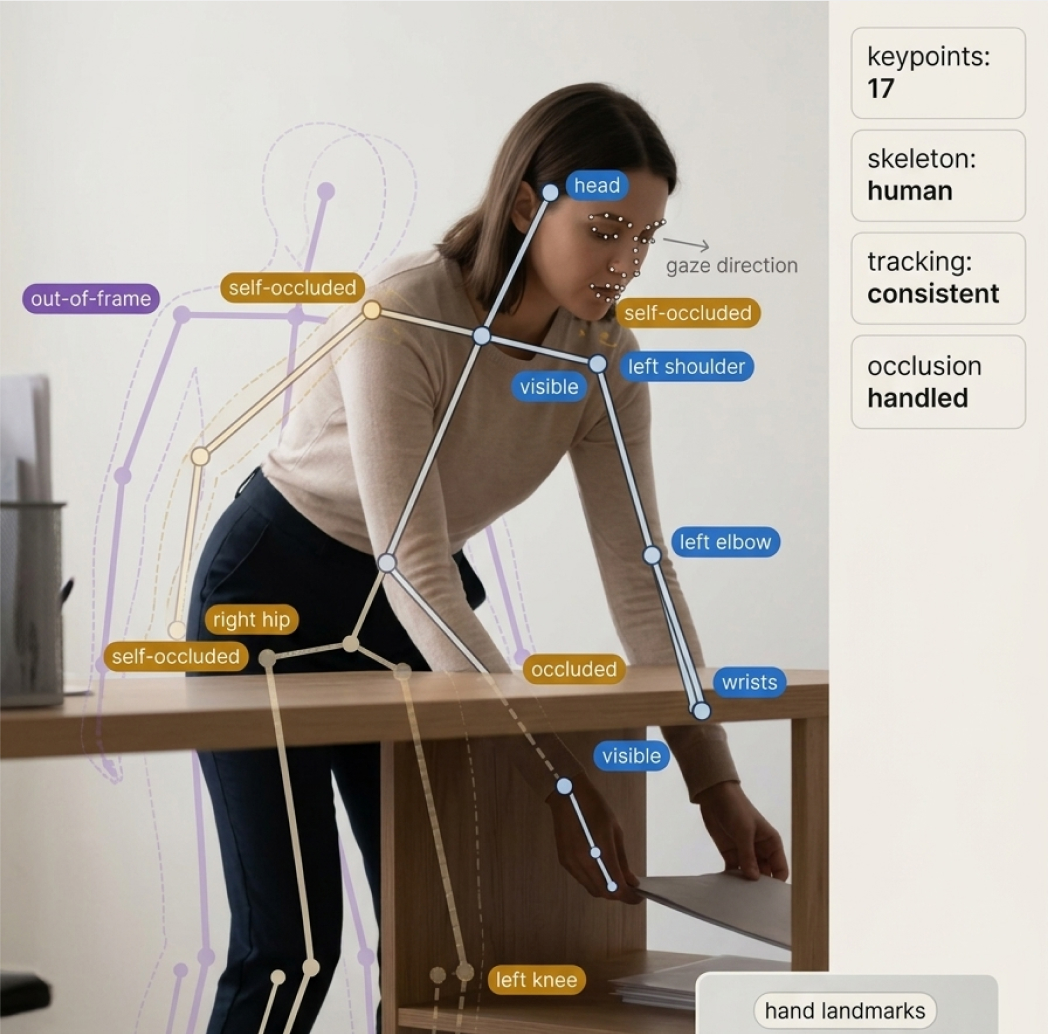
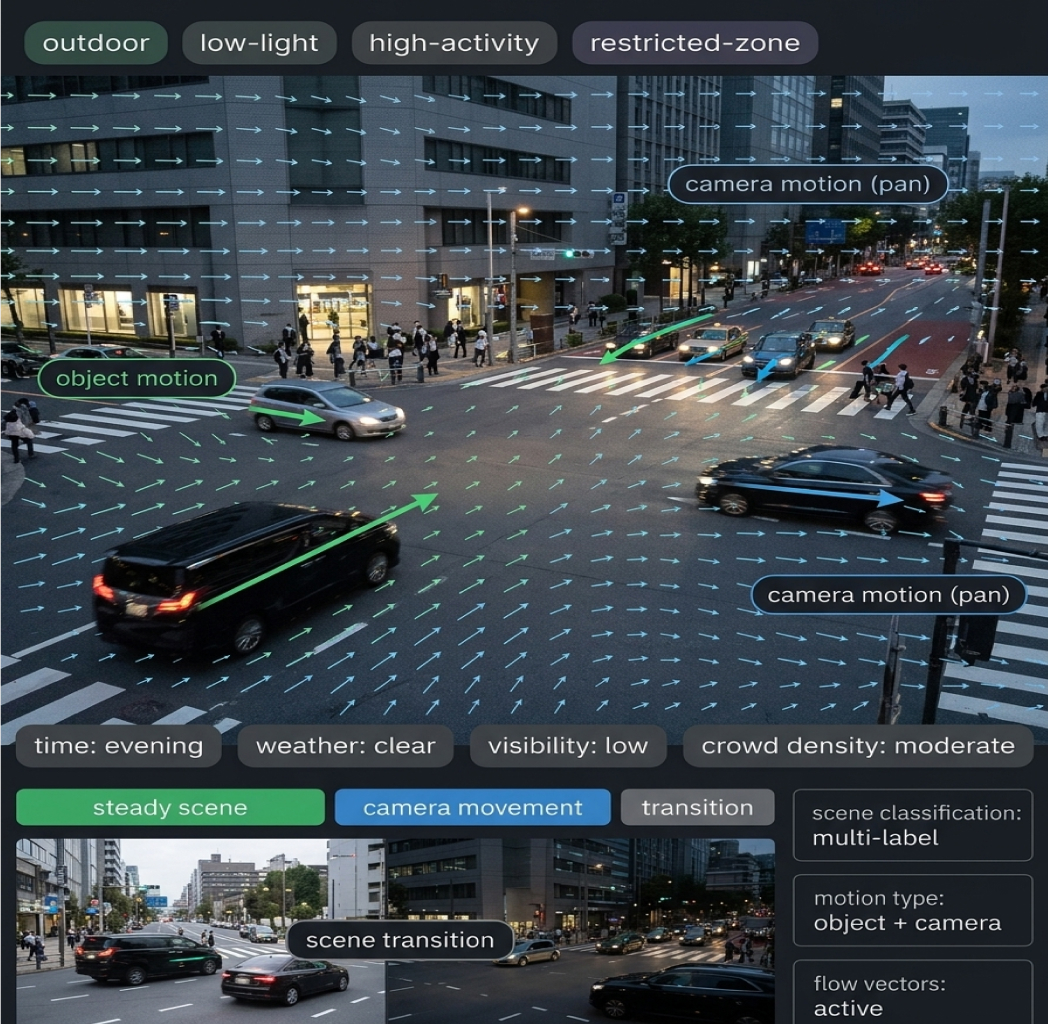
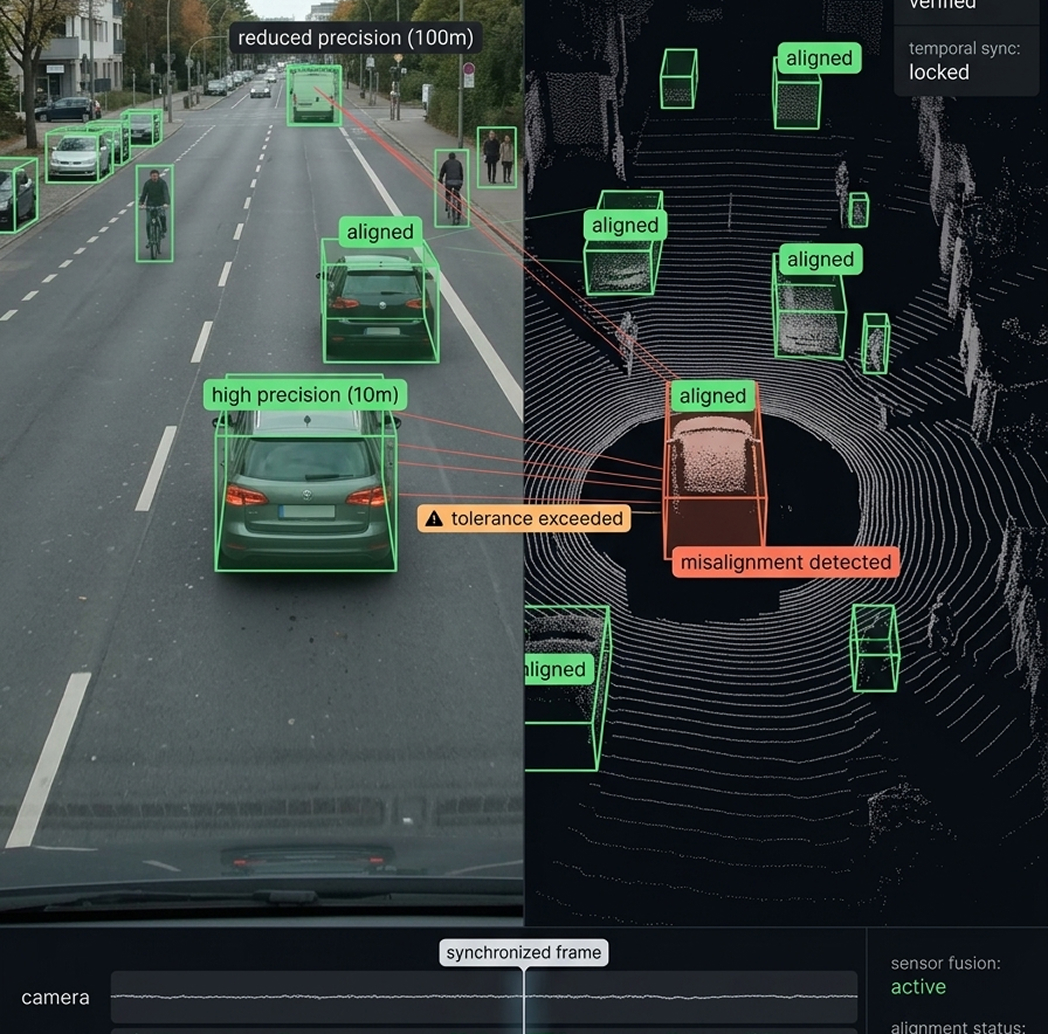
Bounding box annotation and metadata tagging across retail promotional images, powering competitive intelligence solutions for a US-based company.

250K+
Annotations Delivered Monthly98.5%
Annotation Accuracy- Service Image Annotation Services Data Annotation Services
- Platform Client’s Proprietary Data Annotation Tool
- Industry Retail

Precise bounding box annotation for high-resolution aerial river images to train an AI-powered river flow obstruction detection system using the client’s proprietary data annotation tool.
1,500 to 2,000
Images Labeled per Week98%
Labeling Accuracy Rate Maintained<1%
Revision/Rework Rate- Service Image Annotation
- Platform Client’s Proprietary Annotation Platform
- Industry Environmental Monitoring / Forestry

Labeled and validated over 10,000 high-resolution drone images monthly using QuPath to train an AI-powered livestock detection model, delivering 95%+ annotation accuracy.
10K+
Images Annotated Monthly95%+
Labeling Accuracy- Service Image Annotation
- Platform QuPath
- Industry Agriculture (AgriTech)

Labeled over 2500 entertainment content (Movies, TV Series, Trailers) monthly to enable the accurate prediction of the target audience engagement rates and response.
65%
Improved AI Model Accuracy60%
Less Content Categorization Errors4-Month
Faster Model Development- ServiceData LabelingText LabelingVideo LabelingWeb Research
- Platform Client's Predictive Content Intelligence Platform
- Industry Media and Entertainment

