Why Standard Annotation Guidelines Fail on Aerial, Drone, and Satellite Images
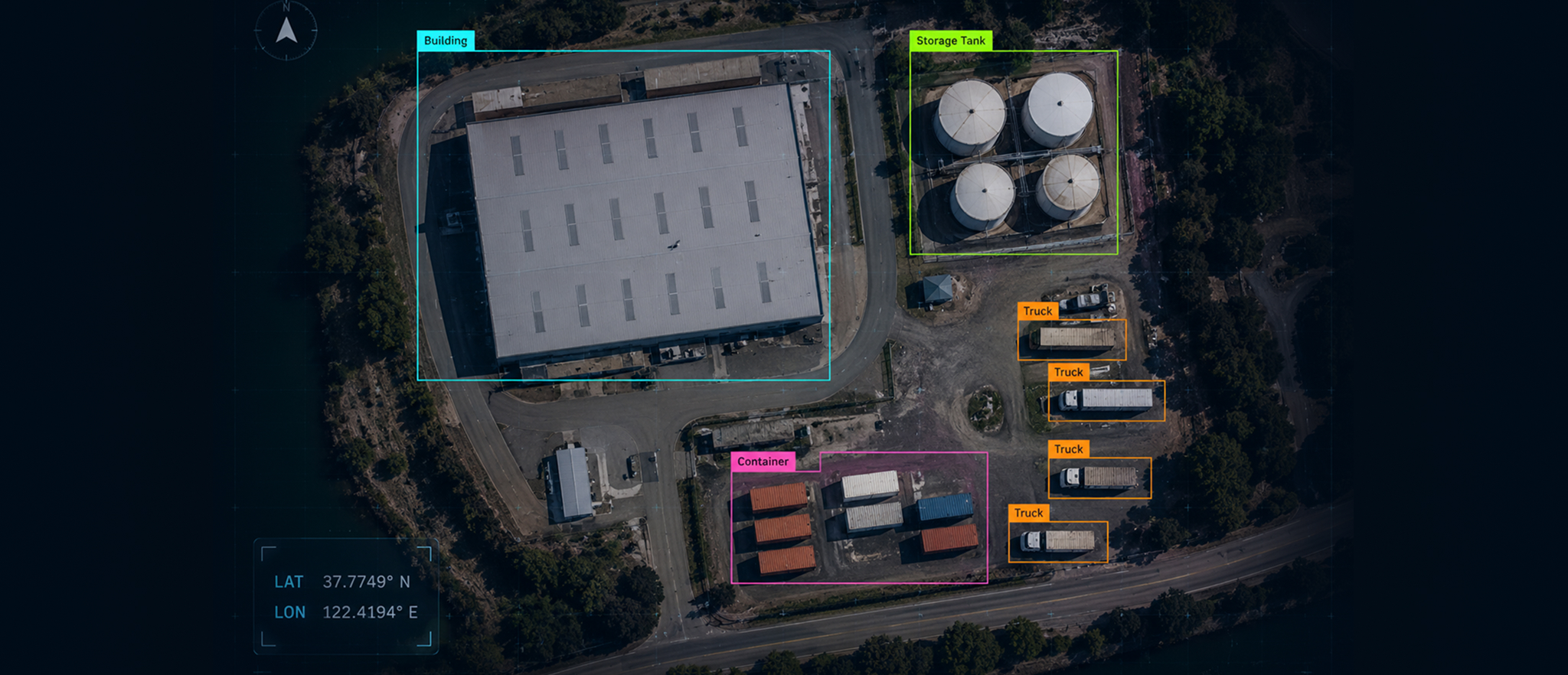
Most teams building AI models on aerial or satellite imagery discover the same thing at the same painful moment: after weeks of annotation, the model underperforms on real-world data. The labels look right. The annotators followed the guidelines. The Quality Assurance (QA) numbers came back clean. And yet the model keeps making the same mistakes.
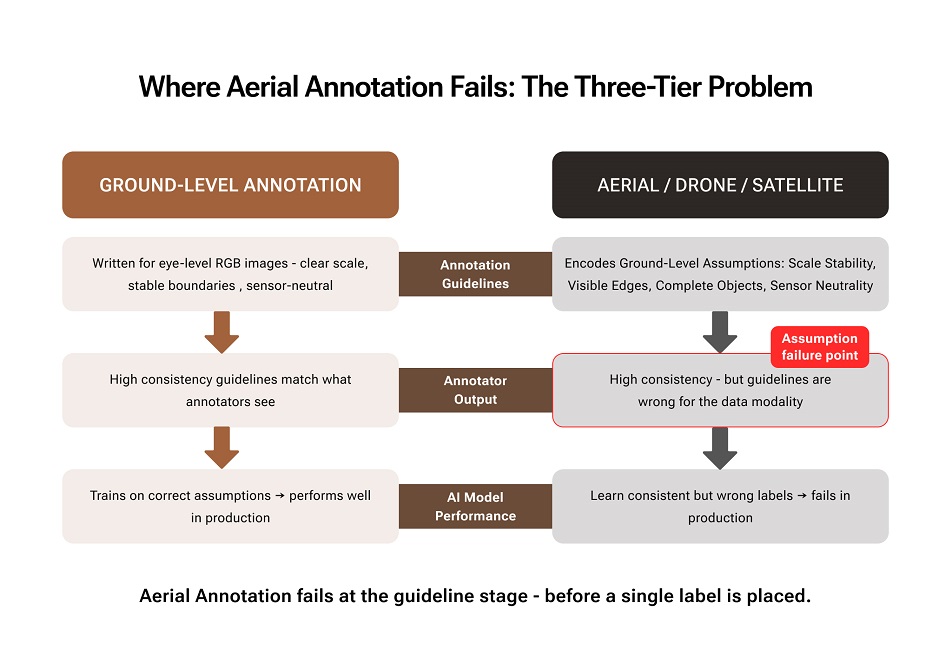
The instinct is usually to blame the annotator’s capabilities, tool calibration, or dataset size. But in many aerial annotation projects, the actual cause lies further upstream — in the data annotation guidelines themselves.
Generic image annotation guidelines, especially those developed for close-range RGB imagery, dashcam footage, CCTV feeds, and street-level object detection, encode a set of visual assumptions that hold perfectly well at eye level. At altitude, those assumptions break. Not in every image, not in a way that is easy to catch on a standard accuracy review, but consistently enough that the model learns the wrong thing and fails precisely when and where it matters most.
Let’s break down the specific ways standard data labeling guidelines fail when applied to aerial, drone, or satellite data, why the standard QA layer often fails to catch these challenges in aerial image annotation, and the annotation protocols that actually work for imagery captured from above.
The Ground-Level Assumptions that Fail at Altitude
Standard data annotation guidelines are based on implicit assumptions about how objects appear in images. Each becomes unreliable the moment a camera leaves the ground.
1. Scale Stability
Street-level cameras operate within predictable, narrow distance bands. A vehicle at 10 meters may look smaller than one at 2 meters, but it still retains a massive, high-density pixel footprint and a distinct, multi-angle silhouette. Annotation guidelines for this environment specify minimum bounding box sizes, margin rules, and label criteria based on that predictable scale.
In aerial imagery, the same vehicle might occupy 400 pixels at 50 meters altitude and fewer than 10 pixels at 300 meters. The DOTA v2 dataset — one of the largest aerial object detection benchmarks, with over 1.79 million annotated instances across 11,268 aerial images — documents this directly: the “massive scale variation across different instances” caused by the bird’s-eye view is a primary reason standard detection approaches fail on aerial data.

This creates a concrete annotation problem. Guidelines that specify label criteria around a standard pixel footprint will, at lower resolutions, either miss objects entirely or generate bounding boxes so imprecise they introduce more noise than signal. Yet most guidelines lack a resolution floor, because scale ambiguity in aerial image annotation simply does not exist at street level.
What this means in practice: a guideline that says “annotate every visible vehicle” will produce systematically different datasets depending on flight altitude, even with identical annotators and identical terrain, because visibility itself is altitude-dependent in a way the guideline was never designed to handle.
We confronted these exact scale and visibility challenges during an aerial traffic analysis project for a US government agency. The project involved annotating more than 2,000 aerial images across 8 classes: cars, SUVs, vans, pedestrians, motorbikes, cyclists, trucks, and buses. The core difficulty was not class definition alone, but object visibility across varying image quality, lighting, and density.
Our team solved this with:
- Attribute-tagging guidelines that explicitly accounted for altitude-induced constraints, such as occlusion rules for dense urban foliage
- Manual adjustment of bounding box vertices on low-resolution micro-targets using LabelImg zoom-in feature
- Multi-stage QA pipeline where subject matter experts audited first-pass labels and used consensus scoring to wipe out systemic edge-case noise
This way, we were able to improve the traffic analysis model’s accuracy by 35%.
2. Boundary Visibility
Ground-level objects generally have visible, continuous edges. A pedestrian in a dashcam frame has a clear silhouette against a road or pavement. A product on a retail shelf has distinct edges. Annotation guidelines written around this reality typically instruct annotators to trace object boundaries, draw tight bounding boxes, or perform pixel-level segmentation along visible contours.
Aerial occlusion is structurally different from ground-level occlusion. At ground level, objects hide behind other objects in the foreground. From above, objects do not disappear behind foreground elements — they compress into one another under top-down projection. When cattle stand close together in a feedyard, when vehicles park bumper-to-bumper, when fallen trees overlap in a river channel, the aerial perspective merges them into a single visual mass. There is no occlusion in the traditional sense; there is top-down merging.
The VisDrone benchmark, which compiled more than 2.5 million annotated bounding boxes from drone footage, documents this specifically: in dense scenes, the overlap between adjacent bounding boxes becomes so large that standard detection methods cannot differentiate instances. The annotation guidelines had not failed — they were followed correctly. The problem was that the guidelines assumed an object had a distinct boundary, and at altitude, many objects simply do not.
We encountered this directly in an aerial data annotation project for a German drone technology company. Our annotators were working with 75,000 high-resolution aerial images of river systems, tasked with identifying obstructions — fallen trees, debris clusters, and accumulated vegetation — that block water flow. The standard bounding box instruction (“draw a tight rectangle around the obstruction”) broke down immediately for long, irregular tree trunks that crossed at angles, debris clusters that blended with the edges of shallow water, and partially submerged formations at image borders. The project required building a custom reference document that replaced the generic bounding-box rule with object-specific coverage criteria based on actual aerial water-flow context—a set of aerial data annotation guidelines with no equivalent in any ground-level annotation framework.
3. Object Completeness
Ground-level annotation guidelines generally assume that objects are either fully visible or not visible at all. There is an understanding of partial occlusion, but the core assumption is that the annotated object has a recognizable form and is reasonably complete within the frame.
From an altitude, object completeness is determined by image resolution, sensor tilt, and flight geometry — none of which the annotator controls. A cow photographed from directly above at 100 meters altitude appears as a compressed oval with no visible features that identify it as a cow. The same animal at a slight camera tilt from 60 meters may show enough body geometry to be unambiguously identified. An annotation guideline that says “label cattle” without specifying which visual cues constitute sufficient evidence for confident labeling will produce inconsistent results among annotators working on the same dataset.
A 2025 PLOS ONE study on observer annotation reliability in aerial wildlife imagery found this directly. Even among expert annotators working on the same images, agreement on fine-grained species classification dropped from 99% for broad morphological categories to 75% for narrower classifications — driven primarily by image spatial resolution and texture attributes rather than annotator competence. The guideline defined what to label, but it did not specify what a sufficient view looks like at altitude or how to handle images where poor resolution makes confident identification impossible.
We encountered a similar problem in a drone annotation project for an AgriTech company, where we annotated 10,000+ drone images per month to train a livestock detection model. At feedyard altitude, cattle frequently compressed to the point where their individual forms blurred into one another in dense groupings. The solution was not retraining the annotators on cattle recognition — they already knew what cattle looked like. Instead, we redesigned the annotation instruction: ovals rather than rectangles to match the actual top-down body geometry, explicit occlusion-handling rules for merged animals, and documented thresholds for minimum visible animal area required before labeling.
4. Sensor Neutrality
Ground-level image annotation guidelines are almost entirely agnostic to the sensor that captured the image. The annotation guideline tells annotators what to label; it says nothing about sensor characteristics because, at ground level, sensor variation rarely changes an object’s appearance enough to matter.
In aerial and satellite imagery, the sensor is part of the annotation problem. For instance, at high altitude, a cloud passing between the sun and the ground doesn’t just make the image darker; it changes the spectral quality of the light hitting the camera sensor. If the downwelling light sensor (DLS) fails to calibrate for that split-second shift, a blue SUV in the shade suddenly yields pixel-level radiometric values different from those of a blue SUV in direct sunlight. To the computer vision model, they look like two entirely different objects.
Confirming this vulnerability, researchers Swaminathan et al. (2024) observed that “Unmanned aerial vehicle (UAV)-acquired multispectral images commonly suffer from radiometric inaccuracies due to changing illumination produced by intermittent cloud cover,” a phenomenon that directly undermines the consistency of downstream classification algorithms. Camera tilt angle, flight altitude, vibration-induced blur, and lens distortion all influence how an object’s boundaries and spectral signature appear in the final image.
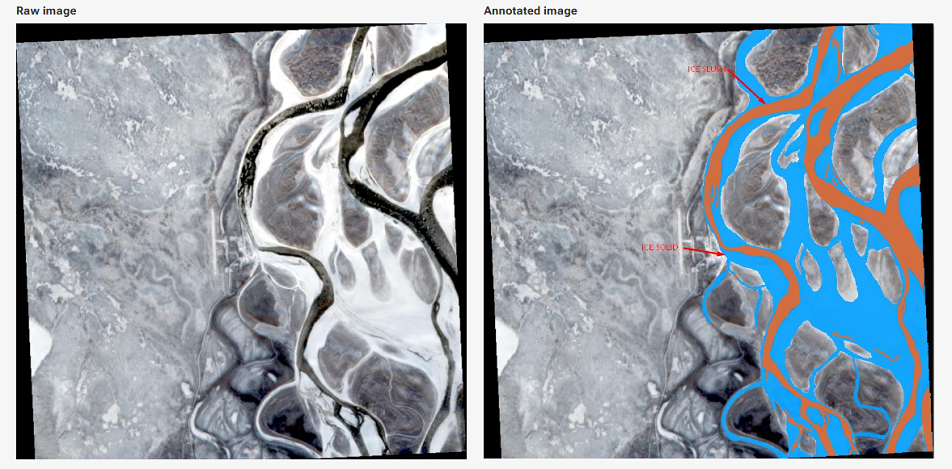
For satellite annotation purposes, this means the same physical object can appear to belong to a different class depending on when the image was captured, at what altitude, and under what lighting conditions. Our geospatial image annotation project for a European environmental monitoring company illustrates this at scale. The project involved pixel-wise labeling of 8,500 satellite images of river systems across three seasonal states — winter freeze, spring thaw, and summer flow — into three classes: Water, Ice-Solid, and Ice-Slush. In practice, the tonal gradients between Ice-Solid and Ice-Slush shifted dramatically across seasons and capture conditions. Ice-Slush in a spring image could be radiometrically indistinguishable from Ice-Solid in an early summer image under different lighting. The sensor distortion satellite imagery labeling challenge was not identifying ice — it was that the sensor-dependent appearance of ice made the same instruction produce inconsistent results depending on capture conditions, which the guideline had never encoded.
5. Clear-Scene Continuity
Ground-level annotation guidelines often assume the scene is visually stable enough for objects to remain distinguishable across frames or images. Aerial imagery breaks that assumption. Cloud shadows, haze, snow cover, water glare, smoke, seasonal vegetation, and overexposure can change class boundaries without changing the underlying object.
This matters because weather artifacts do not always look like noise. A shadow may look like water. Snow cover may hide road edges. Haze may erase small vehicles. Sun glint may make water, ice, or metal surfaces appear as a different class. Without weather-specific rules, annotators begin making case-by-case judgments, resulting in inconsistent training signals.

Why Standard QA Fails on Aerial Data
The problems discussed above are annotation-layer failures. But there is a compounding problem: the standard quality assurance protocols used to check annotation work are usually designed around the same ground-level image assumptions, so they often fail to detect issues caused by specific factors affecting images captured from drones, satellites, or other aerial devices/vehicles.
1. Inter-Annotator Agreement (IAA) for Aerial Image Annotation
Inter-Annotator Agreement (IAA) — the standard measure of labeling consistency — assumes that if two annotators independently label the same image similarly, the labels are correct. In aerial annotation, this assumption is unreliable. Two annotators can agree on an incorrect label because both are applying the same flawed guideline to an ambiguous aerial image. The PLOS ONE study referenced earlier found that agreement metrics for aerial wildlife images varied significantly by spatial resolution and image texture — meaning IAA was measuring annotator consistency against a guideline that was itself resolution-blind.
For instance, let’s assume a labeling rule says, “If an object is a passenger vehicle but features an open or separate rear cargo bed, label it as a Truck; otherwise, label it a Car/SUV.” But a drone flying at 300 meters altitude on a partly cloudy day casts a shadow over a tiny, 12-pixel SUV at 300 meters, and two independent annotators both misinterpret the dark pixel gradient as an open cargo bed and label it a “Truck.” Now, your IAA metric will register a perfect but misleading 100% agreement score on a completely corrupted data point. This shows how high IAA on aerial data can mask systematic labeling errors that only become visible when the model fails on production data.
2. Standard Sample-Based Annotation Review for Aerial Images
Standard accuracy review samples completed annotations and checks them against a known, correct reference. In aerial projects, this works well for common, clearly visible object instances but fails on the edge cases that drive model performance: sub-threshold objects near the minimum pixel floor, partial-overlap occlusions in dense scenes, and seasonally variable spectral signatures in satellite imagery. These cases also appear infrequently enough in random sampling that they do not trigger accuracy thresholds — until the model encounters them at scale in production.
Uniform batch review treats all images in a dataset as equally challenging. Aerial data is not uniformly challenging: winter images have different annotation difficulty from spring images of the same terrain; low-altitude images have different annotation density requirements than high-altitude images of the same area. Reviewing them in undifferentiated batches means the hard cases receive proportionally less scrutiny.

QA Protocols Built for Aerial, Drone, and Satellite Annotation Workflows
The aerial and satellite annotation projects that avoid re-annotation cycles and model failure patterns share a set of QA practices that are not part of standard ground-level annotation workflows.
Resolution-Tiered Annotation Rules
Rather than a single annotation guideline with a single minimum-size threshold, effective aerial annotation specifications define different labeling criteria for different altitude ranges and GSD (Ground Sampling Distance) values. Objects below the usable signal floor are explicitly excluded from labeling rather than left to the annotator’s judgment. This eliminates the inconsistency between annotators who label small objects and annotators who do not.
Capture-Condition Cohort Review
Instead of reviewing images as a single undifferentiated dataset, images are grouped by capture condition — altitude range, season, weather state, sensor configuration — and reviewed within those groups. This makes systematic guideline failures visible: if annotators in the spring-thaw cohort are consistently disagreeing on Ice-Slush boundaries but the winter cohort shows high agreement, the problem lies in the guideline’s handling of a specific capture condition, not in annotator quality. We used this approach in the satellite annotation project for the environmental monitoring company, assigning dedicated sub-teams to each seasonal dataset and rotating reviewers between seasonal teams to catch cross-cohort inconsistency.
Automated Annotation Drift Detection
In large-scale aerial projects with extended timelines, annotators’ interpretations shift subtly over time even when guidelines remain unchanged — a phenomenon known as annotation drift. This is particularly acute in aerial data because the high visual variability between images means annotators are constantly making micro-judgment calls that can gradually diverge from baseline. In the satellite segmentation project, our team built a custom drift detection script that analyzed clusters of related images — the same river bend, same season, different time points — to identify shifts in labeling behavior across time and between annotators, flagging anomalies for Subject Matter Expert review before they propagated into the full dataset.
Object-Specific Edge Case Libraries
Standard QA workflows document errors after they occur. Aerial annotation projects require edge-case libraries built before annotation begins — visual reference guides with annotated examples of the specific ambiguous scenarios the aerial perspective creates: merged objects at altitude, objects at the minimum pixel threshold, objects with sensor-distorted boundaries, objects obscured by cloud shadow. For instance, in the river obstruction detection project, the QA lead maintained a live edge-case library, updated after each bi-weekly calibration session with the client, converting ambiguous scenarios into documented reference cases to reduce annotator error.
IAA Tracked by Capture Condition
Aggregate inter-annotator agreement on aerial datasets can look acceptable while masking severe disagreement on specific image subsets. IAA should be computed separately for each capture-condition cohort and for each object class within each cohort. This is more work than aggregate IAA, but it is the only way to detect the specific failure modes introduced by aerial annotation across altitude bands, seasonal states, and sensor configurations.
Semi-Automated Boundary Assistance
For pixel-level segmentation tasks on aerial imagery, edge detection algorithms that flag probable class boundaries — which human annotators then accept, refine, or override — substantially reduce the time required to trace complex, irregular boundaries while keeping human judgment in the loop.
This was the exact operational pivot required for the European environmental monitoring project mentioned earlier. To improve annotation speed and consistency, our team used a computer vision-based edge-detection solution that analyzed RGB gradients and suggested likely class boundaries. Human annotators reviewed, refined, or overrode those suggestions, reducing manual tracing time by approximately 30% while retaining full control over final label placement.
Note that AI-assisted pre-labeling tools — including foundation models like Segment Anything Model (SAM) — can accelerate annotation throughput on aerial data, but they carry the same baseline assumption failures as manual guidelines: they were trained on ground-level image distributions. A model that segments objects accurately at street level will systematically under-segment at altitude, because the visual features it learned to detect — visible edges, typical object geometry, predictable scale — are the same features that aerial perspective compresses or removes. Using AI assistance for aerial data pre-annotation without GSD-aware calibration shifts the problem from manual annotator inconsistency to automated annotator inconsistency.
Five Questions Every Aerial Annotation Schema Must Answer
Before aerial annotation begins on any drone, UAV, or satellite captured images, the annotation schema needs to address five questions that ground-level guidelines do not ask:
- What is the altitude range and GSD range across this dataset, and what is the minimum pixel threshold for each object class at each resolution tier?
- How does occlusion manifest for the specific object types in this dataset at the relevant altitude, and what does “complete enough to label” mean in that context?
- Which capture conditions (season, weather, sensor configuration, flight geometry) create visual ambiguity for the classes being annotated, and how does the guideline handle each one?
- What is the calibration protocol for annotators across different capture condition cohorts, and how will inter-annotator agreement be measured within those cohorts rather than in aggregate?
- How will annotation drift be monitored for a dataset of this volume and duration?
Teams that invest in preparation at the guideline stage avoid the costly realization during model validation that the training data reflects annotator judgments about an imprecise specification rather than the ground truth about what the model needs to learn.
Get the Guidelines Right before Annotation Begins
Getting the guidelines right before annotation begins is the decision that determines everything else. If your next aerial, drone, or satellite project is still in the planning stage, that is the right moment.
Start every aerial annotation project with schema design and ontology development as the first step – before a single label is placed.

Rohit Bhateja, Director - Digital Engineering Services & Head of Marketing
Rohit Bhateja, Director of Digital Engineering Services and Head of Marketing at SunTec India, is an award-winning leader in digital transformation and marketing innovation. With over a decade of experience, he is a prominent voice in the digital domain, driving conversation around the convergence of technology, strategy, customer experience, and human-in-the-loop AI integration.