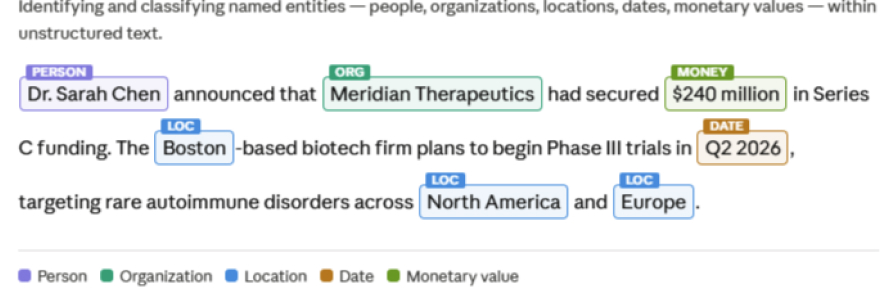
Confidence in AI Outputs Starts with Certainty in Training Data
Get that Certainty with Specialized Data Annotation Outsourcing
The gap between a model that demos well and a model that performs in production is almost always a data quality problem. Our data annotation services solve this with pipelines that leverage both automation and human expertise, precisely where each delivers the most value.
Prominent data annotation tools (CVAT, V7, LabelBox, Supervisely) for faster pre-labeling
Domain specialists for edge cases, subjective judgment, cultural nuance, and preference comparisons
Send an Inquiry
Send an Inquiry
SERVICES
Data Labeling Services, Custom-Built for the AI Problems You Are Solving
From Computer Vision, NLP, and Conversational AI to Multimodal AI Applications
A perception model learning to detect obstacles has nothing in common with an LLM learning to follow instructions — except that both fail when their training data is wrongly labeled. Because we understand how fundamentally different training data needs can be, our data tagging services ensure that your training data is designed for the architecture consuming it.
Text Annotation Services
Description: Train reliable NLP architectures by replacing "noisy" automated labels with human-verified text labeling services. By creating high-quality, structured text training datasets that reflect specific industry logic, we help ground AI decision-making so it does not misinterpret terms, nuances, or cultural context.
Description: We provide high-fidelity image labeling services to support complex computer vision tasks across diverse industries—from medical imaging to retail analytics. By leveraging manual validation and multi-layer QA, we ensure your models accurately recognize objects, boundaries, and context.
Video Annotation Services
Description: While automated tools can "track" objects, they frequently fail during complex movements, lighting shifts, or when objects pass behind one another. Our human-in-the-loop video labeling service substantially reduces "tracking drift" and "identity-switching" through careful review and annotation, ensuring your models get the right understanding of motion.
Audio Annotation Services
Description: Reduce word error rates across diverse environments, enhance the inclusivity and accuracy of your speech-to-text (STT) models, and ensure your voice-activated systems remain functional across global accents and challenging acoustic conditions with our audio and speech labeling services.
Multimodal Data Annotation Services
Description: Bridge the gap between disparate data streams to create a unified feature space with our multimodal data annotation services. By synchronizing text, image, and audio timestamps, we enable your AI to learn how to perform complex "contextual reasoning."
Sensor Fusion Data Annotation Services
Description: In high-stakes environments like autonomous transport or industrial robotics, "close enough" isn't an option. Our sensor fusion data labeling services, which synchronize 2D and 3D data, deliver the spatial accuracy that safety-critical applications demand.
Linguistic Data Annotation Services
Description: Our AI annotation services provide deep-dive linguistic analysis—covering dialect, grammar, emotional subtext, intent, and cultural context—ensuring your AI understands language the way native speakers use it, not just the way a dictionary defines it.
Description: Train reliable NLP architectures by replacing "noisy" automated labels with human-verified text labeling services. By creating high-quality, structured text training datasets that reflect specific industry logic, we help ground AI decision-making so it does not misinterpret terms, nuances, or cultural context.
Description: We provide high-fidelity image labeling services to support complex computer vision tasks across diverse industries—from medical imaging to retail analytics. By leveraging manual validation and multi-layer QA, we ensure your models accurately recognize objects, boundaries, and context.
Description: While automated tools can "track" objects, they frequently fail during complex movements, lighting shifts, or when objects pass behind one another. Our human-in-the-loop video labeling service substantially reduces "tracking drift" and "identity-switching" through careful review and annotation, ensuring your models get the right understanding of motion.
Description: Reduce word error rates across diverse environments, enhance the inclusivity and accuracy of your speech-to-text (STT) models, and ensure your voice-activated systems remain functional across global accents and challenging acoustic conditions with our audio and speech labeling services.
Description: Bridge the gap between disparate data streams to create a unified feature space with our multimodal data annotation services. By synchronizing text, image, and audio timestamps, we enable your AI to learn how to perform complex "contextual reasoning."
Description: In high-stakes environments like autonomous transport or industrial robotics, "close enough" isn't an option. Our sensor fusion data labeling services, which synchronize 2D and 3D data, deliver the spatial accuracy that safety-critical applications demand.
Description: Our AI annotation services provide deep-dive linguistic analysis—covering dialect, grammar, emotional subtext, intent, and cultural context—ensuring your AI understands language the way native speakers use it, not just the way a dictionary defines it.
PROCESS
Our Data Annotation Service Workflow: AI-Assisted, Human-Verified
For Scalable, Enterprise-Grade AI Training Data
To handle the massive throughput of global AI projects while maintaining granular "human-in-the-loop" oversight, our data annotation outsourcing company combines automated labeling tools with rigorous multi-stage quality control to deliver a secure, transparent training data pipeline.
1
Schema Design & Ontology Development
The domain specialists in our team collaborate with you to define annotation guidelines that minimize ambiguity, maximize inter-annotator agreement, and align with your model's actual learning objectives.
2
AI-Assisted Pre-Labeling
We select the right data labeling tool for your data type and complexity, and generate initial annotations across your dataset — dramatically accelerating throughput on routine patterns.
3
Expert Review & Label Correction
Every AI-generated label undergoes “domain specialist review” —trained professionals with subject-matter expertise relevant to your vertical— for context-dependent judgments and edge cases handling.
4
Quality Assurance & Delivery
We implement multi-pass review, inter-annotator agreement metrics, and consensus adjudication for disputed labels, delivering production-ready annotations in preferred formats/methods.
CLIENT SUCCESS STORIES
It's all about results.
The Proof is in the Pipeline
Discover how we’ve helped businesses across 50+ nations bridge the gap between "lab-ready" and "market-ready" AI/ML applications by solving their most complex training data challenges.
Bounding box annotation and metadata tagging across retail promotional images, powering competitive intelligence solutions for a US-based company.
Precise bounding box annotation for high-resolution aerial river images to train an AI-powered river flow obstruction detection system using the client’s proprietary data annotation tool.
Labeled and validated over 10,000 high-resolution drone images monthly using QuPath to train an AI-powered livestock detection model, delivering 95%+ annotation accuracy.
Labeled over 2500 entertainment content (Movies, TV Series, Trailers) monthly to enable the accurate prediction of the target audience engagement rates and response.
AI Data Annotation Services: Prominent Tools We Use
The Infrastructure that Keeps Annotation Consistent at Any Volume
The infrastructure behind our data labeling and annotation services is optimized for control and speed. This tech stack, implemented within our AI data preparation workflow, enables us to remain predictable at scale, auditable under scrutiny, and dependable when models encounter real-world variability.
Labelbox
SuperAnnotate AI
CVAT
Dataloop
Scale AI
V7
Keylabs
Label Studio
labelImg
Segments.ai
CloudCompare
Supervisely
WHO WE SERVE
Engineering AI Training Datasets for Sector-Specific Metadata and Logic Requirements
And Edge Cases that Generic Training Datasets Can Not Handle
Outsource data annotation services to SunTec India to ensure that your AI performs with the precision your industry demands. For every sector we serve, we develop annotation ontologies and labeling schemas from scratch—built around your domain's specific logic, terminology, and failure scenarios. We also configure the annotation workflow to match your use case, rather than fitting your project into a rigid, pre-existing process.
Agriculture
Semantic Segmentation for Crop Monitoring
Image Categorization for Livestock Management
Bounding Boxes for Pest & Disease Detection
Polygonal Annotation for Field Mapping
Multi-spectral image labeling for soil health detection
Autonomous Vehicles
Bounding boxes/cuboids for 2D & 3D object detection
Keypoint annotation for pedestrian intent prediction & road user protection
Polyline annotation for HD map creation & lane-marking systems
Sensor fusion annotation for 3D road and scene perception
Temporal tracking across frames for safe navigation & collision avoidance
IT & SaaS Companies
3D point cloud/LiDAR annotation for robotics, AI/VR
Are Your AI Training Datasets Truly Aligned to Model Performance Goals?
Fix It Before Your Model Hits Production
Most annotation problems aren't visible until a model fails in production. By then, the cost — in retraining cycles, delayed deployment, and lost confidence in the system — is significant. Don’t wait for a failure to find the friction. Partner with an experienced data annotation service provider to architect a high-fidelity data pipeline that guarantees production-ready intelligence.
FAQ - Frequently Asked Questions
AI Data Annotation Services
We deliver annotated datasets in all major formats — JSON/JSONL, COCO, Pascal VOC, CSV, Parquet, and others — depending on your training framework and pipeline requirements. Our data delivery methodology is equally flexible: delivered to an S3 bucket, Google Cloud Storage, Azure Blob Storage, or directly exported to your platform. Every delivery includes the annotated dataset, annotation guidelines, a quality report, and documentation of the data schema, so your team has full visibility into how and why labels were assigned.
Yes. We offer both a free sample and a paid pilot — depending on how much validation you need before committing. If you want a quick read on output quality and annotation style, request a free sample, and we'll process a small batch of your data so you can evaluate our data labeling service firsthand. If you want to validate the full workflow — tool compatibility, delivery format, turnaround, and quality at scale — we can initiate a paid pilot using your actual data in your real environment. Write to us at info@suntecindia.com to get started.
We're platform-agnostic. If your team is already running a managed annotation environment, such as Labelbox, V7, Scale AI, CVAT, Prodigy, or any proprietary data labeling platform, we integrate directly into your existing workspace, preserving your data schema, ontology definitions, and labeling workflows. If not, we select the right labeling platform based on your annotation type, data modality, and pipeline requirements, and handle setup.
It happens quite often. So, our team is prepared to handle it. Our annotation services for machine learning applications handle mid-project changes through a structured re-calibration process:
Update the annotation guidelines
Re-train affected annotators on the revised taxonomy
Run a fresh calibration exercise on sample data to verify consistency
Audit previously labeled data to determine whether re-annotation is needed or whether the existing labels can be mapped to the new schema
Our goal is to absorb the change without restarting the project and without introducing inconsistency with the training data you've already received.
Yes. In our experience as a data labeling service provider, we’ve found that specialized AI applications rarely have linear training data requirements. So, when you need additional capacity, we onboard and calibrate new annotators within one to two weeks — including project-specific training, guideline review, sample annotation exercises, and accuracy benchmarking against your existing ground truth. This means new annotators enter production at the same quality standard as your current team.
All annotated datasets, raw data, and project-specific annotation guidelines developed during the engagement are the client’s intellectual property upon project completion. We do not retain copies, reuse client data to serve other clients, or repurpose your annotation guidelines for other projects.
Our data annotation company defines turnaround expectations based on dataset volume, annotation complexity (e.g., bounding boxes are faster than pixel-level segmentation), the number of label categories, and your QA requirements. We share a detailed project plan with milestone-level delivery dates before work begins, so you know exactly what to expect and when. We can also handle expedited timelines by structuring the team and workflow accordingly.
Our annotators are trained to flag ambiguous instances rather than guess the labels. Flagged cases are escalated to the project's QA lead, who either resolves them using the existing annotation guidelines or, if the case falls outside the guidelines, routes them to your team for a definitive ruling. That ruling is then documented, added to the project's annotation guidelines as a new reference example, and communicated back to the full annotation team.
Yes. We regularly work with client-provided annotation platforms — whether that's your own Labelbox or CVAT instance, a proprietary internal tool, or any other environment your team has standardized on. We export annotated datasets in the format your ML pipeline requires — COCO, YOLO, Pascal VOC, or custom specifications — so your engineering team can ingest the data without additional conversion steps.
Our data annotation operations are ISO-certified for data quality and security, HIPAA-compliant, and GDPR-compliant. All annotators operate under strict NDAs, and your data is handled exclusively within secure, access-controlled environments. We do not retain, repurpose, or share client data beyond the scope of your project.
Pricing is determined on a project-by-project basis, based on the scope and complexity of the work, including factors like the annotation type, dataset size, number of label classes, data modality, quality assurance requirements, and whether specialist review is needed. After an initial scoping discussion, we can provide a detailed custom quote. To get started, contact us at info@suntecindia.com.