The Necessity of Human Validation in Brand Protection Models
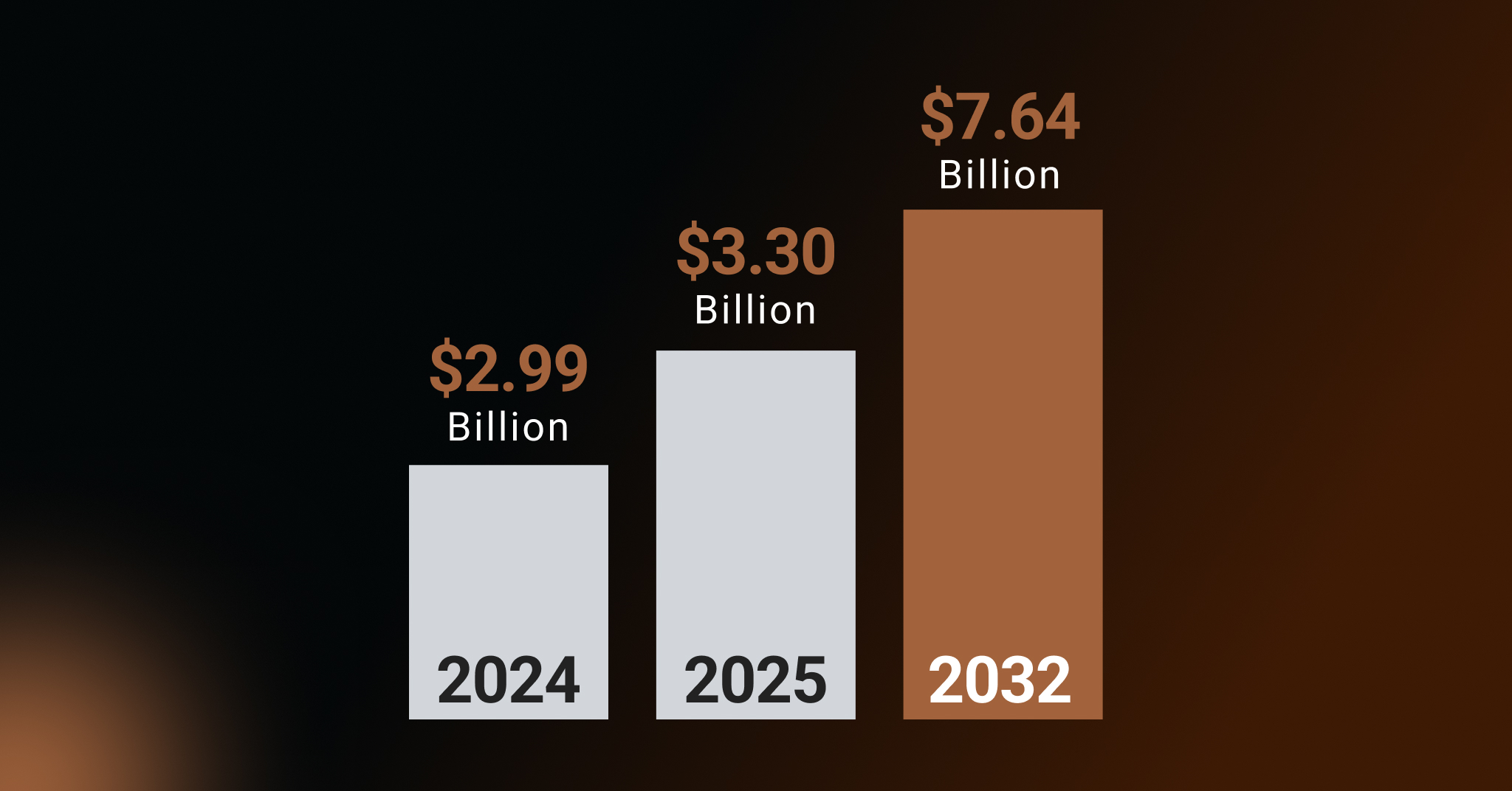
Table of Contents
- The Scope and Limits of Fully Automated AI-Powered Brand Protection Software
- What Human-in-the-Loop Review Means for Brand Protection Enforcement Quality
- HITL vs. Fully Automated Brand Protection: Where Each Model Performs Best
- Brand Protection Scenarios where Human Review Outperforms Automation
- Key Reasons Why Human-in-the-Loop Brand Protection Workflows are More Defensible
- How to Operationalize Human-in-the-Loop Brand Protection Approach
- The Real Advantage: Building a Brand Protection Platform that Escalates Intelligently
- FAQs: Human Validation in Brand Protection Models
Large language models have cut the time needed to create a convincing phishing campaign from 16 hours to five minutes. In a November 2025 Reuters-reported lawsuit, Google alleged a text-phishing operation created nearly 200,000 fraudulent websites in 20 days while impersonating Google, USPS, and E-ZPass.
This is the new reality for brand protection platforms.
AI is no longer just helping attackers create fraudulent content faster. It is increasing the volume, variation, and adaptability of brand abuse itself. As phishing sites, cloned brand assets, fake seller identities, and impersonation attempts multiply faster, purely automated defenses become easier to overwhelm, evade, or misdirect. That is where human-in-the-loop brand protection measures become critical, as a control mechanism, to validate ambiguous signals, prevent wrongful enforcement, and govern high-consequence decisions.
The Scope and Limits of Fully Automated AI-Powered Brand Protection Software
A fully automated brand protection platform does one thing exceptionally well: scale. It crawls listings, scores similarity, flags suspicious sellers and domains, clusters likely violations, and applies rules-based escalation across marketplaces, social platforms, and websites — continuously, at a volume no analyst team can match.
Multimodal AI has raised that ceiling further. By combining image, text, logo, and pricing signals into a single model, leading platforms catch counterfeit and impersonation patterns that single-signal analysis misses. Amazon uses this approach to analyze product images, text, and pricing together in its anti-counterfeit work — and it shows in detection coverage.
Such a model holds as long as the problem is high-volume, repetitive, and unambiguous. But it breaks when detected cases are forwarded for enforcement. That’s primarily because a suspicious signal doesn’t always indicate an actual case of brand abuse.
- A listing that looks counterfeit may belong to an authorized reseller.
- A social profile that looks abusive may be a legitimate regional partner.
- A risky domain is not sufficient evidence for a takedown — it needs more proof to justify the enforcement request.
At that point, the platform isn’t facing a detection problem anymore — it’s facing a judgment call. And judgment is precisely what automation cannot reliably make.
What Human-in-the-Loop Review Means for Brand Protection Enforcement Quality
Human-in-the-loop brand protection workflow is not the same as manual brand protection. It is a workflow architecture in which AI handles surveillance, prioritization, and evidence assembly, while humans review selected cases before irreversible action is taken.
That distinction matters significantly. In a manual workflow, analysts spend time hunting for violations. In a HITL workflow, AI identifies and organizes likely violations first, while human reviewers focus on the cases where context, nuance, or consequences matter most. Human-in-the-loop brand protection workflows are also AI-assisted at the review layer. AI can surface precedents, summarize case evidence, pre-score risk, and guide reviewers to the signals that matter most.
In AI brand protection, HITL typically appears at points such as:
- Seller legitimacy reviews
- Impersonation validation
- Suspicious-domain approval
- Account recovery decisions
- Trademark escalations
- Evidence verification
The role of the human reviewer is not to repeat what the machine already did. It is to interpret the context that the machine cannot reliably resolve.
Read More
SunTec India Helps a Leading Brand Protection & Revenue Recovery Platform with Data Services
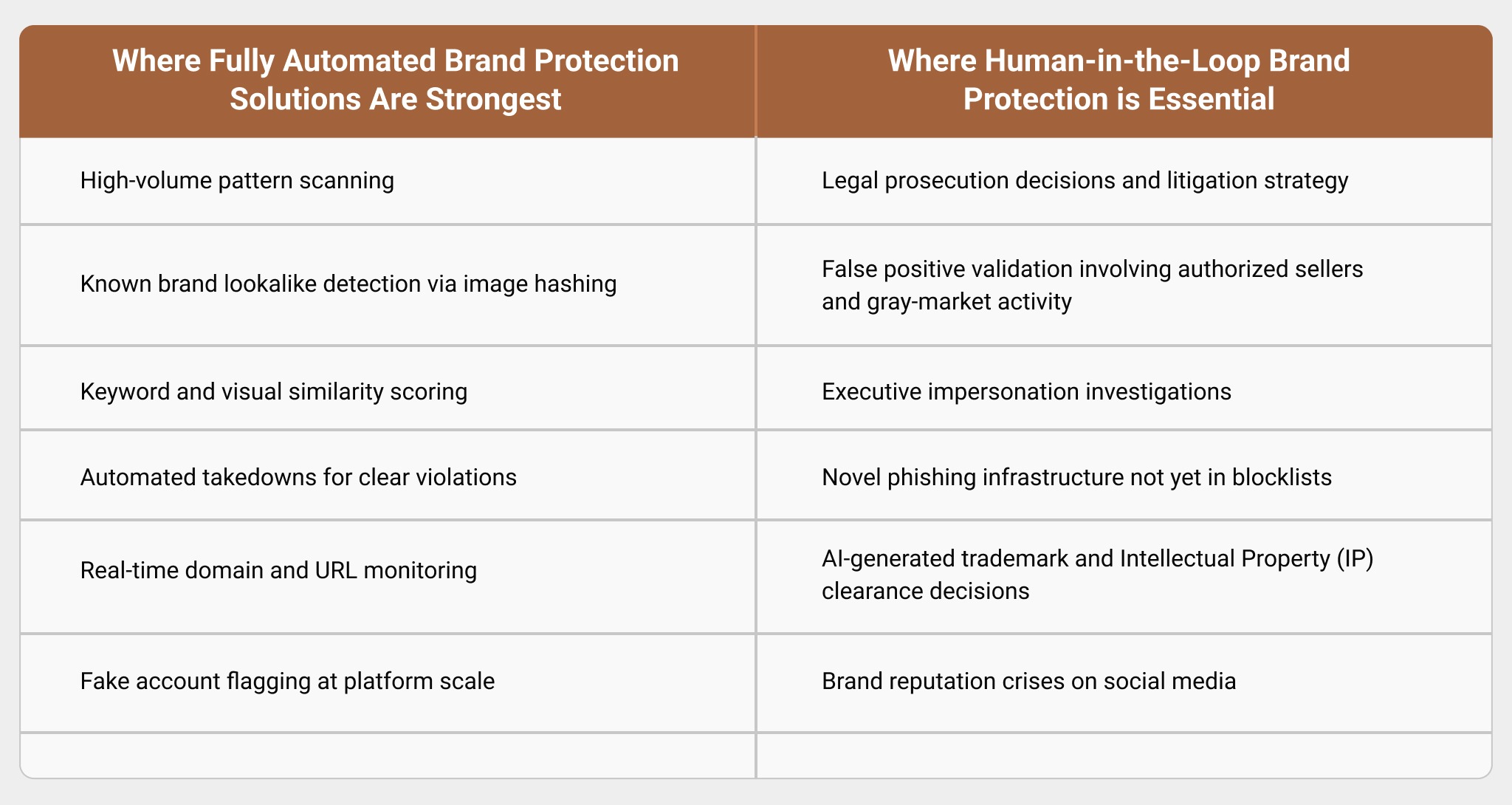
HITL vs. Fully Automated Brand Protection: Where Each Model Performs Best
A fully automated model is built for speed, coverage, and first-pass triage. Human-in-the-loop brand protection models are built to ensure superior decision quality with adequate evidence. The former performs well when the signals are clear, repetitive, and low-risk. The latter is better suited to cases involving ambiguity, gray-market activity, nuances of impersonation, partner relationships, or enforcement consequences that may affect brand reputation and legal defensibility.
Platform-Level Moderation AI Is Now Part of Brand Protection Workflows
AI-powered brand protection platforms no longer operate in isolation. In practice, they now work alongside platform-level moderation AI that already filters risk before a brand team reviews a case.
- Amazon says its proactive controls block more than 99% of suspected infringing listings before a brand has to report them.
- Meta says its newer AI systems can analyze signals such as misleading bios, fake fan sentiment, and deceptive associations with public figures or brands to detect impersonation.
- Google says AI helps it block hundreds of millions of scammy Search results every day and catch 20 times more scammy pages, while its Ads and Shopping policies explicitly target misrepresentation and counterfeit products.
- TikTok Shop has also made platform moderation part of brand protection, reporting that it took down more than 450,000 products for IPR violations between July and December 2024 and published dedicated safety and IPR reporting to support the rights owners.
That changes the nature of human-in-the-loop brand protection workflows. Expert review is no longer only about validating what a brand’s own AI finds. It is also about interpreting what platform-native moderation has already suppressed, what it may have missed, and what requires escalation beyond automated policy enforcement.
In other words, modern HITL workflows increasingly sit between two layers of automation: the brand’s own detection systems and the moderation AI already operating inside major online marketplaces and social platforms. That is one more reason why human validation in brand protection models is necessary.

Brand Protection Scenarios where Human Review Outperforms Automation
1. Counterfeits: AI Detects, Humans Decide
Counterfeit detection is one of the clearest use cases for automation. AI can scan listings, compare visuals, flag pricing anomalies, detect repeated text structures, and surface suspicious seller behavior at a scale no analyst team can match. That is one reason the category continues to grow so aggressively, with counterfeit prevention accounting for the largest share of the authentication and brand protection market (36% in 2025).
But enforcement is where human review becomes essential. A flagged offer may involve an unauthorized seller, a gray-market channel, a distribution dispute, or a legitimate reuse of brand assets rather than a clear counterfeit. Automated takedowns without validation can damage channel relationships, remove legitimate sellers, and erode trust in the platform.
2. Domain and Phishing Threats: High-Risk Cases that Require Human Review
Domain and phishing threats require automation because the abuse surface is too large to manage manually. But detection alone is not enough when the next step involves enforcement, escalation, or financial risk.
The FBI’s Internet Crime Complaint Center (IC3) reported that Business Email Compromise (BEC) caused $2.8 billion in reported U.S. losses in 2024. That figure makes one thing clear: some of the most damaging phishing-related attacks are not stopped by simply spotting suspicious infrastructure. They succeed because the communication appears credible in context.
A payment request, executive email, or vendor instruction may look normal at first glance while still being fraudulent. That is where human review matters most. AI can help detect suspicious domains, emails, and related indicators at scale, but high-risk phishing cases still require human validation, escalation, and response. In this area, HITL is not a backup layer. It is a necessary control point.
3. Social Media Impersonation: Reputational Decisions that Cannot Be Automated
Social media creates some of the most context-heavy cases in brand protection. Fake profiles, clone pages, hijacked handles, scam ads, impersonated support channels, and misleading creator associations often sit in a gray zone between obvious abuse and brand-adjacent activity.
For instance, a suspicious account may be fraudulent. It may also be a local reseller, an outdated regional page, a former distributor property, or an unmanaged community presence using the brand name informally. Human review matters here because social enforcement is not just about removal. It is about deciding what action protects the brand without creating avoidable reputational or operational damage.
Hence, when it comes to monitoring brand abuse actors on social media, brand impersonation protection should not be treated as a purely automated enforcement problem. One recent industry summary found that 52% of brands experienced a social-media-related cyberattack in 2024. Those consequences are too severe to leave entirely to machine-led decision-making.
4. Trademark and IP: Where AI Discovery Must Pair with Legal-Specific Judgment
Automated systems can flag visual and textual similarity across brand names, logos, packaging, marketplace listings, and digital assets. That makes them valuable for discovery, grouping, and prioritization.
What they cannot reliably do is decide infringement, fair use, enforcement priority, or legal strategy. Similarity is not the same as violation. As genuine AI-generated brand assets become a mainstream practice, that distinction matters more, not less.
Brand protection platforms should use AI where it adds the most value: continuous monitoring, evidence collection, case prioritization, and cross-channel entity matching. But when the next step involves asserting rights, filing a formal complaint, or taking any action with legal or litigation risk, expert human review remains essential. AI can support those decisions, but it should not be positioned as a substitute for legal judgment.
Key Reasons Why Human-in-the-Loop Brand Protection Workflows are More Defensible
For AI-powered Brand Protection Platforms, Human-in-the-Loop is the more mature operating model because it keeps automation where automation is strongest and inserts human judgment where automation reaches its practical limit.
1. HITL Brand Protection Workflows Reduce False Positives
A seller may be flagged for branded keywords, reused imagery, or suspicious pricing and still be an authorized reseller or a legitimate gray-market operator.
For example, Amazon flags a seller listing “Nike Air Max 270” because the listing uses Nike brand terms, reuses official product images, and prices the shoes 30% below the average market price. An automated system may score that as likely counterfeit. But a human reviewer checks the seller record, verifies that the seller is part of an authorized regional distributor network, and sees that the lower price is tied to clearance inventory. The case is closed instead of triggering a wrongful enforcement action.
2. Human Validation in Brand Protection Models Improves Enforcement Quality
A suspicious social account or domain may look abusive based on surface signals, but context can change the case. Human reviewers can distinguish between real impersonation, partner-linked activity, and cases that need more evidence before action.
For example, an Instagram account called @zara.outlet.uae uses Zara’s logo as its profile image, reposts official campaign photos, and promotes “exclusive sale” links in Stories. At first glance, it appears to be a clear case of impersonation. But a human reviewer identifies it as an account run by a licensed local franchise partner promoting in-store inventory in the UAE. Instead of sending an unnecessary takedown, the case is closed or routed to the regional brand team.
3. Human-in-the-Loop Brand Monitoring Ensures Decision Defensibility
It makes enforcement easier to explain. Enterprise buyers want more than an alert. They want to know why a seller was escalated, why a profile was flagged, or why a takedown was approved. Human-reviewed decisions are easier to justify because they are tied to evidence and review logic.
For example, a marketplace listing for “Stanley Quencher” is escalated because it uses the brand name, reuses official product photos, and is priced 40% below other sellers. AI flags it as high risk, but the enforcement team does not rely solely on the score. A human reviewer adds the reasoning:
- The seller is not on the brand’s authorized list
- The packaging in the images differs from the current product packaging
- The linked storefront has already been associated with a prior counterfeit complaint
When the listing is removed, the brand can clearly explain why the case was escalated and why the takedown was justified.
4. Human Monitoring Improves the Brand Protection AI over Time
When analysts and domain experts consistently confirm edge cases, reject weak matches, or validate nuanced violations, they create feedback that improves thresholds, prioritization, and future detection quality for the brand protection AI model.
For example, a brand protection AI may repeatedly flag discounted marketplace listings that use official imagery and branded keywords. Human reviewers then determine that many of those sellers are authorized outlet partners, not infringers, and consistently reject those alerts. That feedback teaches the model to place less weight on discount pricing in similar cases, while giving greater weight to stronger signals such as unauthorized seller history, packaging inconsistencies, or repeat complaints. Over time, the system produces fewer false positives and prioritizes higher-confidence violations more effectively.
How to Operationalize Human-in-the-Loop Brand Protection Approach
HITL works only when reviewers receive clear, decision-ready evidence. In mature platforms, that review layer is often AI-assisted, with systems summarizing case history, surfacing related precedents, and pre-scoring evidence before a human acts. If analysts still have to de-duplicate records, rebuild case history, or connect scattered signals manually, review slows down and costs rise. An effective HITL model depends on two things: structured data and a clear escalation framework. In practice, the strongest setup is risk-tiered.
| What AI does | Where Human Review Steps In | |
|---|---|---|
| Detection | Scans listings, domains, accounts, and content for suspicious signals at scale | Not needed for clear machine-detectable patterns |
| Triage | Scores severity, groups duplicates, and packages evidence | The review team checks whether the case has enough context to act on (routed by risk level) |
| Low Risk | Auto-processes repeat violations, duplicate scam patterns, and clear counterfeit clusters | Usually not needed unless disputed (Automated takedown or suppression) |
| Medium Risk | Flags cases with mixed or incomplete signals | Analysts validate seller legitimacy, impersonation risk, suspicious domains, and takedown readiness (Action, hold, or escalation) |
| High Risk | Prioritizes cases with financial, legal, or reputational impact | Senior reviewers assess BEC (Business Email Compromise), executive impersonation, IP-sensitive actions, and partner-impacting enforcement |
| Feedback Loop | Records review outcomes and decision patterns | Human decisions refine rules, thresholds, and future routing logic |
The Real Advantage: Building a Brand Protection Platform that Escalates Intelligently
The real advantage in human-in-the-loop brand protection models does not come from automating every action. It comes from knowing where automation should stop and where human judgment should take over. That is what makes enforcement more accurate, defensible, and reliable across complex scenarios of brand abuse.

FAQs: Human Validation in Brand Protection Models
Gray-market listings, authorized reseller accounts, and regional partner profiles generate the most false positives. Automated systems flag these based on surface signals — branded imagery, pricing patterns, keyword matches — without the context needed to distinguish a legitimate channel from a genuine violation. Human review is the only reliable control point here.
A well-structured HITL workflow does not slow enforcement — it routes only ambiguous or high-risk cases to human reviewers while automation handles clear violations at full speed. Most platforms under SLA pressure are routing too many cases for review, which eventually slows down the entire process. This fix improves triage while ensuring sufficient human oversight.
Wrongful takedowns damage channel relationships, trigger disputes, and erode trust with the very partners a brand depends on. In some cases, they expose the parties to legal liability and severe monetary consequences. When automated brand protection software fails to reliably distinguish an unauthorized seller from a legitimate distributor, it risks losing trust among its clientele and its market reputation. Human-in-the-loop brand protection approach prevents that from happening.

Rohit Bhateja, Director - Digital Engineering Services & Head of Marketing
Rohit Bhateja, Director of Digital Engineering Services and Head of Marketing at SunTec India, is an award-winning leader in digital transformation and marketing innovation. With over a decade of experience, he is a prominent voice in the digital domain, driving conversation around the convergence of technology, strategy, customer experience, and human-in-the-loop AI integration.