How to Prepare Your Product Catalog for AI Shopping Assistants and Answer Engines: The 2026 Playbook

Table of Contents
- SEO Gets You Ranked. Product Data Gets You Recommended
- Traditional Search Asked For Matches. AI Shopping Asks For Answers.
- Mistakes We See in 80% of Catalog Audits: Gaps That Quietly Impact AI Visibility
- A Practical Framework for Product Data Management: Preparing Your Catalog for AI Shopping Assistants
- The Real Goal Is Not “AI Optimization.” It is Catalog Clarity.
- Is Your Catalog Ready for AI-Led Product Discovery?
The products that appear in AI-generated shopping answers aren’t always the best-reviewed. They’re not always the biggest brands. Consider a mid-sized luggage brand whose listing includes weight, dimensions, TSA compliance, laptop compartment size, and material, versus a larger competitor whose listing relies on broad claims such as “lightweight and durable.” The mid-sized brand is more likely to surface, while the larger one may not. What they have in common with every other product that makes it into AI answers is a cleaner, richer, more consistently structured catalog data.
That’s the shift most eCommerce teams haven’t fully reckoned with yet. AI shopping assistants and answer engines: Google’s AI shopping experiences, ChatGPT shopping, and Amazon’s Rufus don’t retrieve products the way a keyword algorithm does. They reason over product data. They compare attributes, resolve ambiguity, and assemble answers. A catalog with thin descriptions, inconsistent feeds, and missing attributes doesn’t rank lower in that environment; it gets excluded.
SEO Gets You Ranked. Product Data Gets You Recommended
SEO still matters, but AEO changes what product visibility depends on. It relies on product data management. AI shopping assistants are tied to clean, structured, and well-governed catalog data to understand what a product is, where it fits, how it compares, and whether it can be surfaced with confidence. The real requirement is not more layers of optimization on a page. It is stronger control over the product data that powers discovery in the first place.
Four shifts matter more than anything else.
1. Optimization has moved from pages to attributes
In traditional SEO, the page is the main unit of ranking. In AI shopping and answer engines, retrieval often happens at the attribute level. The more complete and structured your product data is, the more retrieval paths an LAG or LLM-powered system has to match your product to a shopper query.
2. Retrieval is now intent-based and query conditional
AI retrieval does not work like simple keyword matching. The same product may be the right answer for multiple prompts, but only if those use cases are encoded in the catalog. A blender can match “quiet for a small apartment” and “high horsepower for smoothie bowls” only when both intents are clearly reflected in the underlying product data.
3. Structured data now supports LLM understanding
For conventional SEO, schema markup mainly helps search engines qualify pages for rich results. For LLM-driven answer engines, structured data plays a deeper role. It gives the retrieval system cleaner inputs and helps the model interpret product identity, attributes, and relevance with less ambiguity.
4. Weak data now leads to exclusion, not just a lower rank
In classical SEO, incomplete pages may still rank lower and remain visible. In AI retrieval systems, thin, inconsistent, or conflicting catalog data often leads to omission. If the LLM or retrieval layer cannot trust the product data, it is more likely to exclude that product and select a competitor with cleaner inputs.
Traditional Search Asked For Matches. AI Shopping Asks For Answers.
In the old model, the product page mainly had to rank, attract the click, and let the shopper figure the rest out. In the new model, the system often tries to summarize the fit before the click. Google’s AI shopping experiences are built to organize products, prices, reviews, inventory details, and places to buy. ChatGPT shopping is built to help users discover, compare, and decide on products inside a conversation. Amazon Rufus is built to answer specific product questions and make recommendations from conversational context.
That means the catalog has to do more than hold product names and short descriptions. It has to support product reasoning.
How AI Shopping Assistants Actually Read Your Catalog
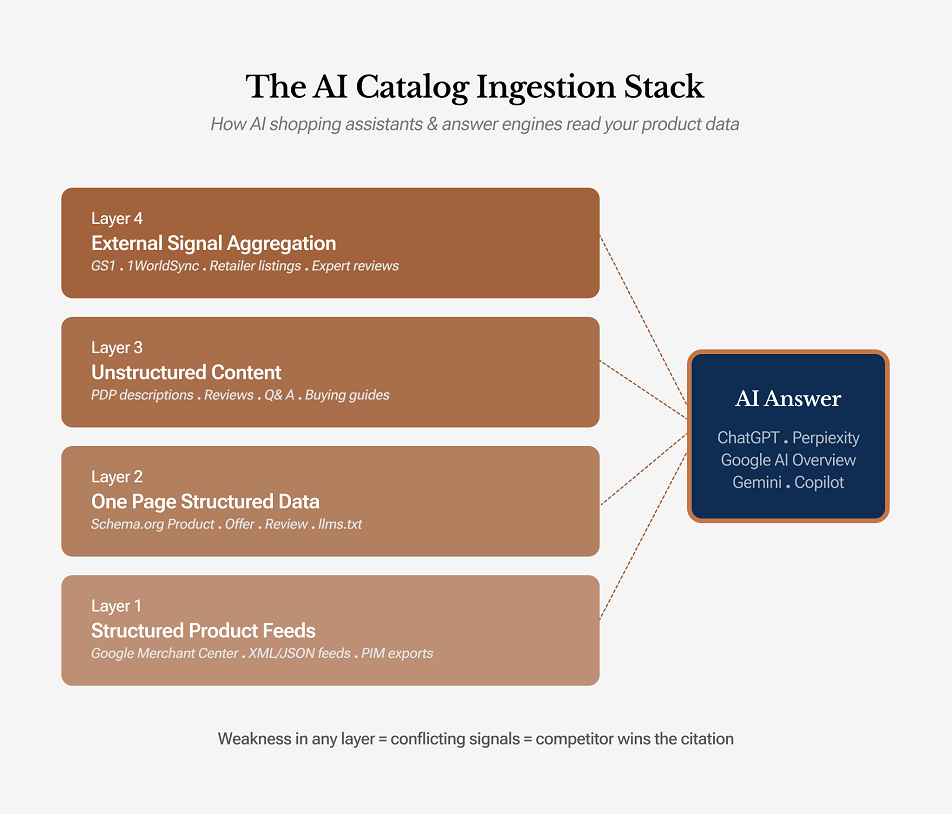
To prepare your catalog for AI shopping assistants, you first need to understand what these systems actually ingest. The common assumption that “the AI just reads my product page” is incomplete. Most modern shopping assistants and answer engines pull product information from a four-layer data stack. Your product is more likely to appear accurately in AI-generated answers only when all four layers align.
Layer 1: Structured product feeds
This includes Google Merchant Center feeds, shopping feeds, and XML or JSON exports from your PIM. This is usually the cleanest and most trusted input because it gives the system canonical product data with minimal ambiguity. It is where AI engines expect to find core facts such as price, availability, GTIN, brand, and primary attributes.
Layer 2: On-page structured data
This includes Schema.org markup such as Product, Offer, AggregateRating, Review, and ProductGroup, along with supporting formats such as FAQ schema and emerging conventions like llms.txt. This layer helps your website describe the product in a machine-readable format. It tells the retrieval system and the LLM exactly what the page represents.
Layer 3: Unstructured product content
This covers PDP copy, bullet points, product descriptions, reviews, and Q&A. LLMs can extract useful meaning from this layer, but only when the content is specific and attribute-rich. Thin promotional copy adds far less value. This is also the layer where contextual details, use cases, and buyer-oriented explanations usually appear.
Layer 4: External product signals
This layer includes product information that appears outside your own website and feed ecosystem, such as marketplace listings, GS1 and 1WorldSync records, third-party specification databases, expert reviews, and editorial buying guides. AI shopping assistants may pull from these sources to validate, compare, or fill gaps in your catalog data. You do not control this layer fully, but it still affects how your products are interpreted. If those external signals match your own catalog data, they reinforce trust. If they conflict, they create ambiguity.
Here is the important part: AI engines do not resolve data conflicts based on source loyalty. They resolve them based on confidence. If your feed says a headphone weighs 250 grams, your PDP says 280 grams, and a GS1 record says 254 grams, the system sees inconsistent evidence. It may leave the detail out, reduce confidence in the product, or choose a competitor with more consistent data. Even one unreliable layer can weaken product visibility.
Mistakes We See in 80% of Catalog Audits: Gaps That Quietly Impact AI Visibility
1. Titles identify the product, but not the buying context
Many product titles tell the system what the item is, but not how it should be matched to shopper intent.
“Women’s Dress Style 4821” gives almost no usable context.
“Women’s Satin Evening Gown with Side Slit for Formal Events” is far stronger because it signals product type, material, and use case.
This matters even more in AI shopping environments, where vague source titles limit how clearly the product can be interpreted and surfaced.
2. Attribute coverage is too shallow
In many catalogs, the product has far more relevant attributes than the system can actually access.
A product may have 25 useful data points, but only 5 are exposed in a structured form. That weakens retrieval for shopper queries tied to fit, compatibility, installation, environmental conditions, or performance requirements.
3. Variant logic is broken
Variant relationships are often fragmented across records instead of being cleanly grouped.
Size, color, pack count, voltage, finish, and compatibility options may exist in the catalog, but without proper product categorization & parent-child structure, AI systems and search engines can misread how those variants relate to the core product.
4. Compatibility data is missing
This is one of the most common and most costly gaps in technical catalogs.
For electronics, accessories, automotive parts, industrial components, and replacement products, compatibility is often the deciding factor. If the system cannot determine what the product fits, it is less likely to retrieve or recommend it confidently.
5. Product descriptions are promotional, not answer-ready
Many descriptions are written to sound persuasive, but not to answer real buying questions.
Terms like “premium quality” or “high performance” add little interpretive value.
Descriptions work better when they state specifics, such as fit range, included components, dimensions, usage conditions, or weight.
6. Reviews and Q&A are treated as secondary content
In strong AI commerce environments, reviews and Q&A are not supporting content. They are product intelligence.
They reveal how shoppers describe the item, what comparison factors matter, and where purchase hesitation begins. When this layer is ignored, the catalog loses a major source of real-world product context.
7. Feed data and on-page data do not align
This is a recurring issue in large catalog environments.
Price, availability, shipping, variant details, or even product identity may differ across feeds, schema, and PDP content. Once those layers fall out of sync, retrieval confidence drops and visibility issues follow.
8. Trust and policy signals are buried
Shipping cost, handling cutoff, return terms, warranty coverage, refund method, and delivery timelines are often pushed to the margins of the product experience. That is a mistake. These signals now shape buying confidence and influence how product information is interpreted across AI-assisted shopping surfaces.
AI-Readiness Scorecard. Take a self-audit
| Parameter | What AI Engines Need | Red Flag Threshold | Quick Test You Can Run Today |
|---|---|---|---|
| Attribute completeness | Full category-appropriate attribute set per SKU | >20% of SKUs missing 5+ core attributes | Export 50 random SKUs and count attributes per category |
| Attribute consistency | Uniform units, formats, and canonical values | Any field with >3 value variants for the same meaning | Pivot your top 10 attributes by distinct value count |
| Taxonomy depth | Multi-parent, faceted, intent-aligned categories | Flat taxonomy with <3 levels of depth | Count levels; count SKUs with only one category path |
| Schema markup coverage | Valid Product/Offer/Review/Rating on every PDP | <90% of PDPs pass Rich Results Test | Run 20 PDPs through Google’s Rich Results Test |
| Use-case tagging | Job-to-be-done, persona, occasion tags per SKU | <30% of SKUs carry any use-case tag | Sample 50 SKUs and count use-case tags per category |
| Freshness & governance | Defined cadence and ownership per data layer | No documented owner or last audit date | Ask: who last audited the attribute set, and when? |
A Practical Framework for Product Data Management: Preparing Your Catalog for AI Shopping Assistants
This is the core operating model. The work is not limited to product copy, schema, or feeds in isolation. AI visibility improves when catalog data is clean, enriched, structured, context-aware, and maintained through a clear data management & governance process.
1. Clean and Normalize the Catalog Foundation
Start by fixing the basics. Standardize units across all fields, remove duplicate SKUs, correct orphan variants, normalize brand names, materials, colors, and dimensions, and clean legacy feed errors or encoding issues.
This matters because AI retrieval systems treat inconsistent product data as a trust problem. If the same brand appears as “Samsung,” “samsung,” and “SAMSUNG ELECTRONICS,” the product cluster becomes harder to interpret confidently.
Done right, every key attribute has one canonical value across every SKU, feed, and destination. This requires rule-based normalization, controlled vocabularies, and exception handling that routes edge cases to human review.
The most common mistake is treating product data cleansing as a one-time cleanup. It is not. Every new SKU, supplier file, or feed update introduces fresh drift.
| Field | Before (messy) | After (canonical) |
|---|---|---|
| Brand | Samsung, samsung, SAMSUNG ELECTRONICS | Samsung |
| Color | Black, Schwarz, Negro, Charcoal-Black | Black |
| Weight | 250g, 0.55 lb, 0.25 kg | 250 g |
| Resolution | 4K, UHD, 3840×2160 | 3840×2160 |
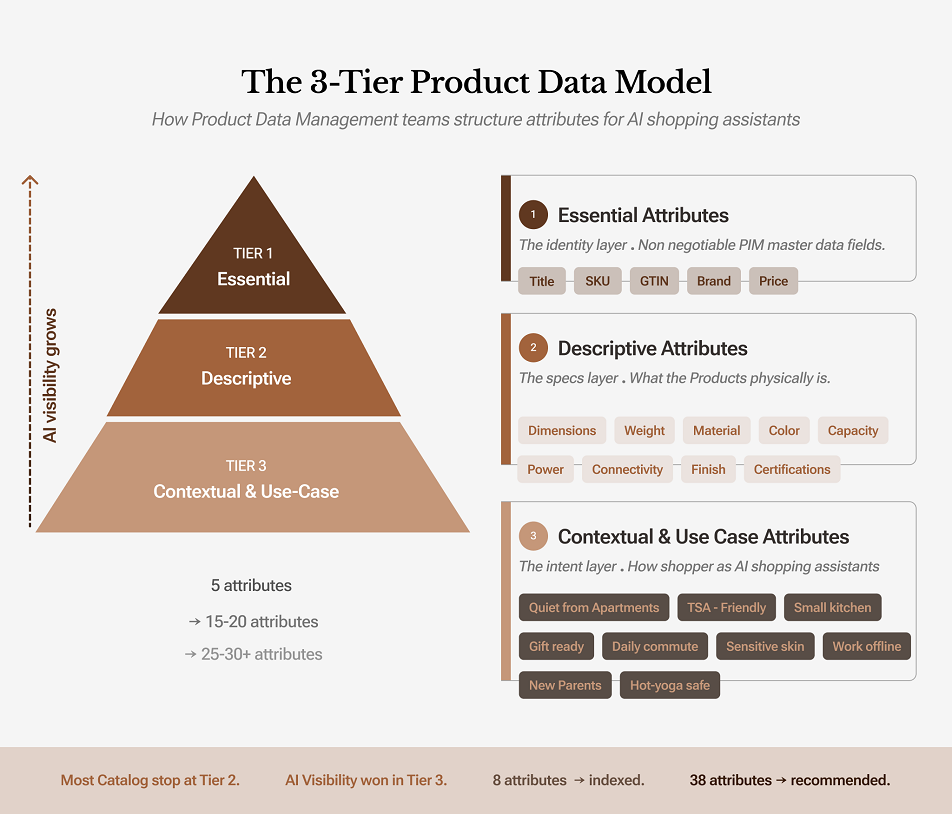
Step 2 · Deep Attribute Enrichment (The 3-Tier Model)
Most catalogs expose only a limited set of attributes such as title, brand, color, price, and sometimes a few basic specifications. That level of product data may support listing and filtering, but it is not enough for AI shopping assistants and answer engines that rely on richer inputs to retrieve, compare, and recommend products. This is where catalog enrichment becomes essential. Enrichment expands the product record beyond basic identifiers and turns it into a more complete, machine-readable source of product intelligence.
A practical way to approach this is through a three-tier attribute model.
Tier 1: core identifiers such as title, SKU, price, brand, and GTIN
Tier 2: descriptive attributes such as dimensions, material, weight, color, and specifications
Tier 3: contextual attributes such as use case, environment, lifestyle fit, occasion, or buyer intent
Tier 3 is where AI visibility expands. That is where products begin to surface for prompts such as “quiet enough for a small apartment,” “good for new parents,” or “works in a carry-on setup.”
What good looks like is not a longer title. It is a richer attribute structure. A backpack should not stop at material, color, and dimensions. It should also include signals such as “15-inch laptop friendly,” “TSA compliant,” “water resistant,” “daily commute,” or “anti-theft zippers.”
The common mistake is pushing all of that context into the visible title or a few lines of marketing copy. That weakens readability and usually leads to keyword stuffing. Enrichment works best when use-case, intent, and fit signals are added as structured attributes that support retrieval, comparison, and answer generation.
3. Refine Taxonomy, Categorization, and Variant Structure
AI systems do not rely only on text. They also use category structure and product relationships to narrow the candidate set before ranking and recommendations begin.
That means flat taxonomies and broken variant logic create avoidable retrieval problems. A yoga mat may belong to Yoga, Home Exercise Equipment, and Meditation Support at the same time. A product may also need a clean parent-child structure for size, color, pack count, voltage, finish, or compatibility-based variants.
Done right, each SKU is mapped to a meaningful category structure that reflects how shoppers think and how AI systems retrieve. Where possible, this should align with recognized taxonomies such as Google Product Category or GS1 GPC, while still supporting your internal faceted model.
The common mistake is either under-structuring or over-structuring. A shallow taxonomy misses buyer intent. An overly nested taxonomy becomes hard to govern and adds little retrieval value.
Example: Taxonomy for a yoga mat
Primary path:Fitness → Yoga → Mats
Secondary path:Home → Exercise Equipment → Floor Mats
Tertiary path:Lifestyle → Mindfulness → Meditation Support
4. Strengthen Machine-Readable Product Layers
Once the catalog foundation is clean, the next priority is making it readable to search and AI systems in a structured way. This includes product feeds, Schema.org markup, variant markup, reviews, ratings, offers, and, where relevant, FAQ schema.
This layer carries much more weight in AI-assisted commerce than it did in older SEO workflows. Product schema, offers, ratings, and grouped variant relationships help machines interpret product identity, price, stock status, and product structure with far less ambiguity.
What good looks like is full schema coverage on active PDPs, clean validation, and exact alignment between structured data and what appears on the live page. The visible page, feed, and markup should describe the same product reality.
The common mistake is publishing a schema that conflicts with the page or feed. If the page says out of stock and the markup says in stock, the trust problem is larger than a simple validation issue.
5. Build Intent-Ready PDP Content, Reviews, and Q&A
When structured fields are limited, LLMs fall back on the content layer. That means your PDP copy still matters, but only if it is useful.
Thin marketing language does not help retrieval. “Premium sound quality” and “high performance” do not answer real questions. Specific content does. A strong PDP explains dimensions, materials, compatibility, use cases, care, setup, and common purchase objections.
This same logic applies to reviews and Q&A. Reviews reveal how buyers describe the product in real language. Q&A reveals pre-purchase friction points. Together, they supply signals that often align more closely with AI shopping prompts than marketing copy does.
Done right, product descriptions follow an attribute blueprint, FAQs are built from real buyer questions, and review modules surface usable signals such as structured pros, cons, and repeated use-case themes.
The common mistake is overwriting. AI systems reward density of useful information, not long brand-heavy copy.
Before · generic description
“YourBrand XM-500 headphones deliver premium sound quality with noise-canceling technology. Experience music the way it was meant to be heard. With long battery life and a comfortable fit, they’re perfect for any listener. Available now in black.”
After · attribute-rich description
“The YourBrand XM-500 is an over-ear wireless headphone built for long-haul travel and daily commutes. The hinges fold flat, dropping the footprint to 6.1 inches; small enough for a personal-item bag. Battery life runs 30 hours with active noise cancellation on, 40 hours off, with a 10-minute quick-charge adding 5 hours. ANC uses eight microphones with three modes (travel, office, ambient). Driver is a 40mm dynamic unit tuned for vocals and mid-bass. Supports LDAC, aptX Adaptive, and AAC codecs. Weighs 255g. Ear cups use memory foam with protein leather; TSA-checkpoint friendly in the included hard case. Ideal for long-haul flights, open-plan offices, and frequent travelers who prioritize foldability and battery life over the deepest bass. Common objections: bass is tight rather than thumping, which audiophiles split on — see Reviews for A/B comparisons against the Sony WH-1000XM5 and Bose QC Ultra.”
6. Add Use-Case and Intent Tagging At Scale
This is one of the most underused levers in catalog preparation. Many product records describe what the item is, but not the situations in which it makes sense.
A blender can be relevant to “quiet blender for a small apartment” and also “high-power blender for smoothie bowls,” but only if those use cases are represented somewhere in the product data. The same applies to backpacks, food processors, yoga mats, office chairs, and nearly every other category.
What good looks like is a defined tagging framework by category, supported by rules, automation, and human validation. Tags should reflect jobs-to-be-done, buyer personas, environments, usage conditions, and real question patterns found in search, support, reviews, or AI referral traffic.
The common mistake is partial coverage. Tagging a few hero products is not enough. AI systems notice gaps and inconsistencies across a catalog more quickly than many brands expect.
Example: use-case tags unlocking AI query visibility
| Product | Traditional attributes | Use-case tags added | AI queries unlocked |
|---|---|---|---|
| Blender, 1200W | Wattage, jar size, color | Quiet operation, small-apartment-friendly, smoothie-bowl ready | “Best quiet blender for apartments” |
| Backpack, 25L | Capacity, material, weight | 15-inch laptop, TSA-compliant, daily commute, minimalist aesthetic | “Backpack for digital nomad, carry-on only” |
| Food processor, 14-cup | Bowl size, motor, accessories | Small-kitchen, quiet, one-handed use | “Food processor that fits in a small kitchen” |
| Yoga mat, 6mm | Thickness, material, weight | Joint-friendly, travel-foldable, eco-material, hot-yoga safe | “Travel-friendly yoga mat for sensitive knees” |
| Office chair, ergonomic | Height, weight capacity, material | Long sitting, lumbar-support, compact desk, back pain | “Office chair for 10-hour workdays with back pain” |
Table 2.1 · Use-case tags multiply the set of AI queries a single SKU can surface in.
7. Product Data Management Has To Function as an Ongoing Operational Discipline
AI catalog readiness is not maintained through occasional cleanup projects. It depends on strong product data management. That means the catalog is actively governed as a living system, not treated as a static content asset.
In practice, this includes continuous control over product attributes, taxonomy, variant relationships, feeds, schema, supplier inputs, and channel-level consistency. It also means building clear ownership, audit routines, validation workflows, and feedback loops so catalog quality does not erode over time.
What strong execution looks like is a repeatable product data management framework with defined owners, update cadences, QA checkpoints, and escalation paths. The goal is not only to keep data current, but to keep it aligned across every place where AI systems, search engines, marketplaces, and shoppers encounter the product.
The common mistake is assuming that once a catalog is enriched, it will stay AI-ready on its own. It will not. Without active product data management, even a strong catalog gradually becomes inconsistent, incomplete, and less retrievable.
This is exactly what active catalog management looks like in practice. When SunTec India worked with a U.S.-based multi-brand home improvement retailer managing 100,000+ SKUs across 70+ brands, the catalog problems weren’t one-time issues — they were ongoing operational ones.
Vendor SKU mismatches, category misalignments, inconsistent product attributes, and multi-channel sync failures were continuously eroding listing quality. Fixing them required standardized templates, automated stock-sync workflows, custom taxonomy rules, and channel-level QA processes—not a single cleanup task. The result was 99% listing accuracy, a 96% reduction in inventory discrepancies, and a 35% increase in traffic.
The Real Goal Is Not “AI Optimization.” It is Catalog Clarity.
A product catalog wins in AI shopping when it explains itself clearly.
- It tells the system what the product is.
- It shows what makes the product comparable.
- It clarifies who the product is for.
- It reduces uncertainty with proof and policy information.
- It stays consistent across page, schema, feed, and marketplace records.
That is the difference between a catalog that is simply available online and one that is ready for AI-led product discovery. In conversational commerce, visibility depends not just on having product pages but on having product data that is accurate, enriched, standardized, and machine-readable.
For brands with large or fast-moving catalogs, this requires more than content updates. It requires end-to-end product data management covering data cleansing, attribute enrichment, taxonomy control, variant management, feed optimization, schema alignment, and ongoing quality governance across channels.
Is Your Catalog Ready for AI-Led Product Discovery?
Evaluate gaps in product data, taxonomy, variants, feeds, and schema before inconsistent catalog signals start limiting visibility.
The SunTec India Blog
Brought to you by the Marketing & Communications Team at SunTec India. We love sharing interesting stories and informed opinions about data, eCommerce, digital marketing and analytics, app development and other technological advancements.