

In the race to automate GTM strategies, a dangerous myth has taken hold: that AI can independently define your ICP and generate flawless contact lists. AI is operational in B2B sales — that much is settled. The real question is whether to trust it with decisions it structurally cannot make — like defining your Ideal Customer Profile.
AI is no longer experimental in B2B sales—it’s operational. McKinsey’s State of AI 2025 reports that 88% of organizations now use AI in at least one business function, with widespread adoption across segmentation, targeting, and go-to-market execution.
That scale of adoption has fueled a risky assumption: that AI can independently define Ideal Customer Profiles (ICPs) and produce reliable email marketing lists. In practice, usage has outpaced value. Gartner finds that 45% of marketing technology leaders say vendor-provided AI agents fail to meet promised business outcomes- most often when those systems are applied to data-dependent decisions like ICP definition and buyer identification.
The issue isn’t AI capability—it’s data integrity. When ICP definitions and contact data are incomplete, inferred, or outdated, AI optimizes for probability rather than commercial truth. The result shows up as misaligned accounts, irrelevant roles, and wasted sales effort.
This is where custom list building services matter. By combining AI-assisted discovery with human verification, they keep ICPs grounded in buyer reality—where precision, not automation alone, drives revenue.
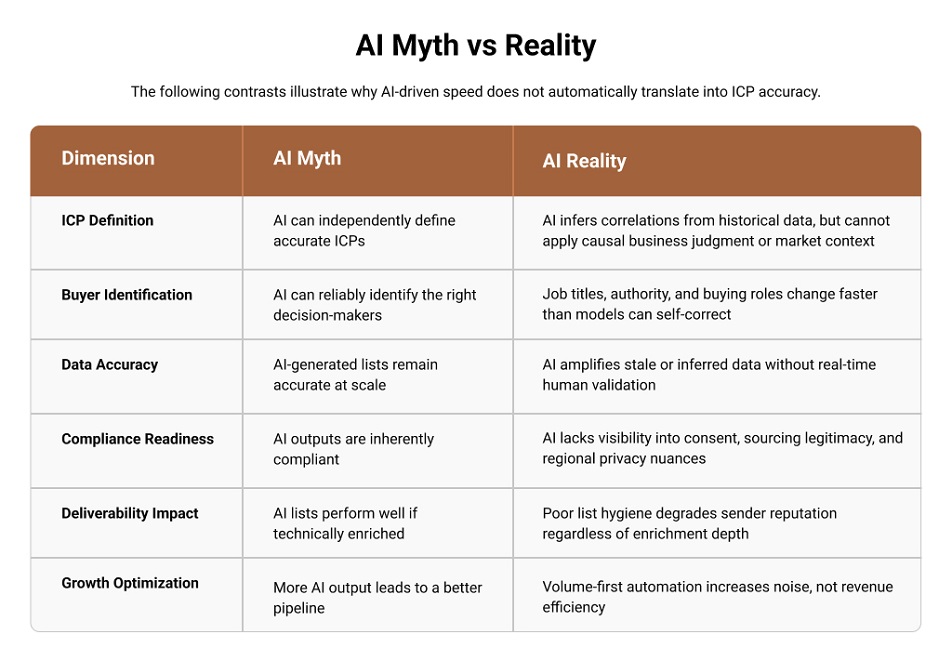
What AI Does Well—and Where It Breaks Down
MIT Sloan Insight!
Research on AI bias and hallucinationsshows that models can generate high-confidence outputs even when the underlying information is incomplete or ambiguous—especially when context cannot be independently validated. In the ICP definition, this dynamic turns uncertainty into a false sense of precision.
AI is effective at processing scale and complexity. It can ingest millions of records, normalize inconsistent fields, and identify statistical patterns much faster than when done manually. In B2B sales and marketing contexts, AI performs well at:
- Grouping companies based on shared characteristics (firmographics, such as company size, and technographics, such as the technology stack they use).
- Detecting correlations across large historical datasets (e.g., company size, industry, tech stack)
- Identifying surface-level similarities between past customers and new prospects
- Estimating the size of a market or segmenting it into smaller, manageable groups that are easier to focus on and sell to
These capabilities make AI highly valuable for exploratory analysis, initial ICP hypothesis generation, and early-stage market segmentation.
However, defining the right ICP and producing usable business email and contact lists requires more than pattern recognition. It requires understanding:
- Why certain attributes matter (causality)
- When they matter in a buying cycle (timing)
- Whether they apply to a specific commercial situation (context)
These are the areas where AI systems face structural limitations in finding genuine buyers, not just more contacts.
Signal vs. Noise: A Necessary Distinction that AI Struggles with
In B2B list building, signal refers to attributes that directly correlate with buying probability, like:
- Decision authority for a specific purchase category
- Budget ownership or documented influence over purchase decisions
- Active buying triggers (expansion, compliance deadlines, system replacement)
- Role relevance aligned to the buyer’s current mandate and buying stage
Noise, by contrast, includes data points that are technically accurate but commercially useless:
- Correct job titles without buying authority
- Valid email addresses tied to inactive or displaced roles
- Companies matching firmographics but operating outside the relevant buying context
AI systems trained on aggregated datasets (internal, third-party, and inferred) struggle to distinguish between these categories because they rely on correlation rather than contextual judgment.
This is how distortion enters AI-led ICP definitions.

Where AI Gets ICPs Wrong: The Structural Causes of ICP Drift and Hallucination
AI hallucinations in B2B targeting are not random errors. They emerge from identifiable system behaviors:
1. Probabilistic Inference over Ground Truth
AI models are designed to predict the most statistically likely output based on patterns in training data. When clear ground truth is unavailable—as is common with org charts, buying roles, and responsibility boundaries—the system fills gaps by extrapolating from similar cases rather than confirming real-world accuracy.
OpenAI explicitly notes that systems like ChatGPT can produce plausible-sounding but incorrect outputs because they are optimized to continue patterns rather than confirm facts—especially when no definitive source of truth exists or when the model lacks visibility into what it does not know.
In list building, this leads to inferred role relevance, assumed authority, or fabricated alignment between titles and buying power.
2. Dependence on Historical and Lagging Data
B2B targeting accuracy depends on the quality of underlying data. According to the Salesforce State of Data and Analytics Report (2025), data and analytics leaders estimate that 26% of their organization’s data is currently untrustworthy.
When AI systems are trained or prompted on datasets with this level of uncertainty, they do not detect “bad” data—they normalize it. The result is ICPs and contact lists that reflect historical averages and inferred patterns rather than current buying reality. These outputs may look statistically sound, but they are operationally fragile—misaligned to real decision-makers, real mandates, and real timing.
In list building, this is how relevance quietly erodes: not through obvious errors, but through confidence built on stale assumptions.
3. Data Aggregation without Contextual Weighing
Modern AI systems often combine data from different sources (such as commercial databases, public websites, or inferred data about a company’s tech stack) and assign a probabilistic confidence score to each data point. These confidence scores measure statistical likelihood (how well the data matches past trends or patterns) rather than commercial veracity (how current the information is).
This creates a critical hierarchy gap, wherein the AI makes decisions about which data to trust or prioritize based on statistical likelihood, not accuracy or timeliness:
- Data Conflict
AI often lacks the heuristic logic to resolve “conflicting” data. For example, a legacy database might show outdated information (like an old job title for an executive), while a recent social media update shows a new job title. The AI might prioritize older, high-confidence data from the reliable but outdated source over newer, potentially more accurate data from a social media update, thus missing the “ground truth”. - Decay Miscalibration
All data does not decay consistently. For instance, details about a company’s headquarters location (firmographics) are stable over time, while specific information about an executive’s responsibilities (such as quarterly mandates) can change rapidly. AI models struggle to account for such temporal data decay. They may treat both data types with the same level of confidence, overlooking crucial recent updates or dynamic changes. - Relevance vs. Authority
AI tends to prioritize semantic relevance (matching a job title) over the authority or real-world significance of that data (whether that person actually has the responsibilities or power indicated by their title).
This shows that the challenge isn’t just bad data—it’s the absence of hierarchy between data points.
Why Human-in-the-Loop Is Essential for Modern B2B List Building
At scale, the limiting factor in B2B list building is no longer automation—it’s decision quality. We’ve already discussed how AI can process signals, but it cannot determine which signals translate into revenue. This makes human-in-the-loop validation operationally necessary.
Human experts do not replace AI outputs; they complete them by:
- Validating whether a role has real buying authority for a specific product category
- Confirming that contact relevance reflects current responsibilities, not legacy titles
- Assessing whether the outreach context aligns with the buyer’s mandate and timing
- Ensuring data usage complies with regional privacy, consent, and channel norms
This shift mirrors a broader enterprise pattern. The Dynatrace State of Observability 2025 report shows that as organizations scale AI, they are investing in control layers to prevent automated systems from drifting away from business outcomes:
- 70% of organizations increased observability budgets this year, and
- 75% plan to increase them again next year, signaling a move from raw automation to governed intelligence.
This is why human-verified contact and email list building services outperform AI-only approaches in real GTM environments: they serve as the governance layer that converts automated signals into revenue-relevant targeting.
Custom List Building Services: What Makes Them Structurally Different
Custom list building is not “manual list building.” It is a controlled system in which AI accelerates discovery through a scalable contact discovery service, while humans validate authority, relevance, and timing.
In practice, this means:
- AI surfaces potential accounts and contacts at scale
- Humans validate ICP fit, buying authority, and relevance
- You get outputs that sales teams can act on immediately: verified contacts mapped to real buying roles, not raw data exports.
For most organizations, building this capability in-house is structurally inefficient because it demands:
- Continuous research,
- Access to multiple premium data sources,
- Rigorous data validation standards, &
- Ongoing oversight to ensure lists remain commercially usable—not just complete
These requirements rarely align with internal sales or marketing team mandates, which are optimized for execution rather than data verification.
As a result, many organizations prefer to outsource list building services, choosing vendors that combine automation with human accountability, enabling consistent delivery of sales-ready lists without diverting internal teams from core revenue work.

Buyer Evaluation Checklist: How to Assess B2B List Building Services in 2026
For buyers evaluating list building partners, the following criteria separate revenue-grade services from volume-driven list building companies.
1. ICP Governance & Control
What to watch for: Vendors who prioritize statistical similarity over human-defined business logic. |
2. Role & Authority Verification
What to watch for: Claims of “decision-maker lists” without explanation of verification methods. |
3. Data Freshness & Continuity
What to watch for: Heavy dependence on static third-party databases. |
4. AI Usage Transparency
What to watch for: Lack of visibility into data lineage or the specific human-to-AI ratio in the production workflow. |
5. Customer Data Enrichment Relevance
What to watch for: Over-enriched records with little sales usability. |
6. Compliance & Deliverability Readiness
What to watch for: Vague assurances of “compliance-ready” data. |
7. Outcome Orientation
What to watch for: Performance framed only around volume and turnaround time. |
|
Final Perspective: AI (By Itself) Can Not Pick the Right Target Buyer for Your Business
AI has permanently changed how fast B2B teams can analyze markets and surface opportunities. What it cannot do is decide which buyers actually matter, right now, for a specific commercial outcome.
ICP definition is not only a data exercise—it is a revenue decision. And revenue decisions require accountability, context, and verification.
As AI-generated data becomes cheaper and more abundant, competitive advantage will shift to organizations that impose discipline on automation. That discipline is human-verified, custom list building—where ICPs reflect buyer truth rather than statistical likelihood.
That is the real business case for B2B custom list building services in 2026 and beyond.
