Why AI Data Incompatibility Happens: A Deep Dive into the Training Data Lifecycle

Table of Contents
- The Enterprise Reality behind AI Data Incompatibility
- Why AI Data Incompatibility Matters
- Where AI Data Incompatibility Emerges in the Training Data Lifecycle
- How Organizations Can Solve AI Data Incompatibility
- The Bottom Line For Enterprise AI — Prevent AI Data Incompatibility to Secure Your AI Investments
Enterprise AI is not failing because organizations lack ambition. It is failing because the underlying data foundation is often too fragmented, inconsistent, and operationally unprepared to support the development of reliable AI models.
The gap between model ambition and data reality is becoming harder to ignore. Gartner found that, on average, only 48% of AI projects make it into production, and for those that do, it takes eight months to move from prototype to production. In a separate study, Gartner reported that 63% of organizations either do not have, or are unsure whether they have, the right data management practices for AI. The same research predicts that through 2026, organizations will abandon 60% of AI projects that are not supported by AI-ready data.
The issue is not data scarcity alone. Most enterprises already have large volumes of operational, transactional, behavioral, and customer data. The problem is that these datasets are often inconsistent in structure, fragmented across systems, poorly governed, or lacking the context AI systems need to interpret them correctly. This is why so many AI programs look promising during pilots but struggle when teams try to scale them across real workflows.
- According to IBM’s report on AI adoption challenges, 45% of business leaders are concerned about data accuracy or bias, while 42% say they lack sufficient proprietary data to customize AI effectively.
- ISG’s 2025 State of Enterprise AI Adoption report found that only 31% of prioritized AI use cases are in production.
- The ISG report also highlights that only 25% of AI initiatives have actually achieved expected ROI (Growth AI), while nearly half are still using AI only to do existing work faster or cheaper (Safe AI).
AI data incompatibility sits at the center of this problem. When data from different systems, teams, or lifecycle stages cannot be reliably integrated, interpreted, validated, or governed for machine learning use, teams spend more time repairing inputs than improving models, and scaling production becomes far more difficult than achieving pilot success.
This article examines why AI data incompatibility has become one of the biggest barriers to enterprise AI, where it shows up across the data lifecycle, and what leadership teams can do to reduce it before it slows delivery, weakens trust, and limits business impact.
The Enterprise Reality behind AI Data Incompatibility
Most enterprises do not have a data volume problem. They have a data alignment problem.
AI systems depend on consistent signals across multiple environments: Enterprise Resource Planning (ERP) platforms, Customer Relationship Management (CRM) systems, product databases, analytics stacks, application logs, Internet of Things (IoT) feeds, support systems, partner data, and third-party sources. Each of these environments is typically built for a different purpose, owned by a different team, and governed under different rules. When AI initiatives try to combine them, inconsistencies surface quickly.
A customer may be identified one way in the CRM, another way in the commerce platform, and differently again in the support environment. A timestamp may be stored in different formats across regions. Business definitions, like “active customer,” “order value,” “churn risk,” or “return event,” may vary by department. Product attributes may be complete in one system and sparse in another. None of these gaps is necessarily fatal for reporting, but they become serious when models need reliable, repeatable, and context-rich inputs.
That is why AI often exposes enterprise data weaknesses faster than traditional analytics ever did. ISG notes that enterprise AI outcomes depend on how well organizations integrate data, processes, and governance into high-value workflows. Its 2025 report found that as more use cases move into production, complexity in data integration, measurement, and tooling maturity continues to shape outcomes.
The Strategic Gap is Also Becoming More Visible at the Executive Level
IBM found that 81% of CDOs (Chief Data Officers) prioritize investments that accelerate AI capabilities and initiatives, yet only 26% are confident their organizations can use unstructured data to deliver business value. In the same study, 80% said they have started developing diverse datasets to train AI agents, but 79% also admitted they are still early in defining how to scale and govern them.
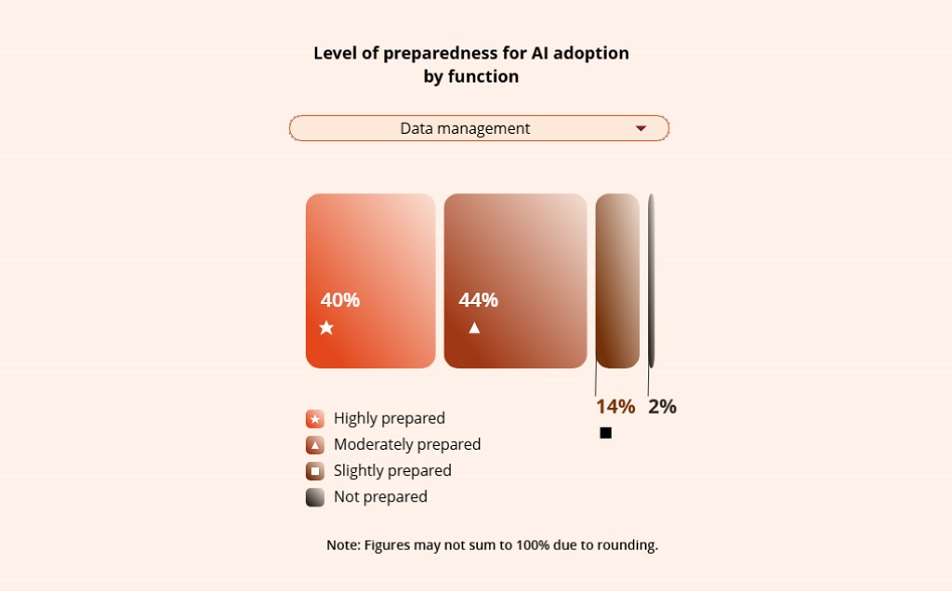
That explains why many organizations can demonstrate AI potential in controlled settings but struggle when real enterprise conditions come into play. Deloitte’s 2026 State of AI in the Enterprise report found that only 42% of organizations believe their strategy is highly prepared for AI adoption, and even those organizations report being less prepared on data, infrastructure, risk, and talent.
The result is a familiar executive pattern. Pilots advance. Interest grows. Budgets are approved. Then the scale slows down because the underlying data cannot support reliable production behavior. For example, Capgemini’s World Quality Report 2025 found that 89% of organizations are piloting or deploying GenAI augmented workflows, yet only 15% have reached enterprise-wide implementation. The biggest barriers were data privacy risks (67%), integration complexity (64%), and hallucination and reliability concerns (60%). While that research is specific to quality engineering, it reflects a broader enterprise problem: the path from experimentation to scale is being limited by integration, trust, and data control.
Why AI Data Incompatibility Matters
AI data incompatibility matters because it changes the economics of enterprise AI.
When data does not align across systems, AI teams spend more time reconciling records, standardizing schemas, repairing features, checking labels, and validating outputs. That increases delivery cost, slows experimentation, and makes production timelines less predictable. The issue is not only technical. It affects operating leverage, governance burden, and how quickly leadership can trust AI in customer, risk, and revenue-related workflows.
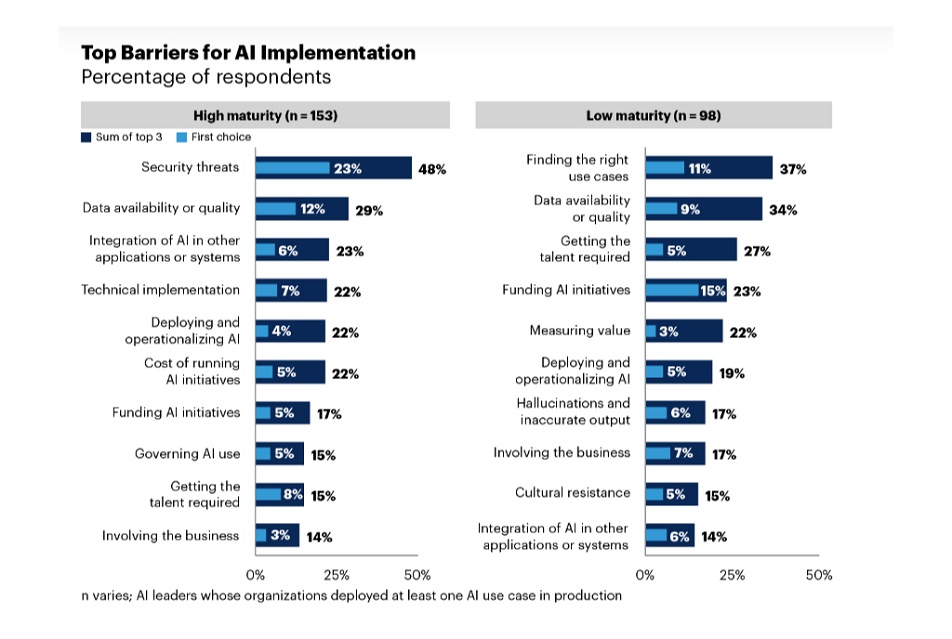
This challenge persists even in more mature organizations. Gartner’s 2025 AI maturity research found that data availability and quality remain among the top AI implementation barriers, cited by 34% of low-maturity organizations and 29% of high-maturity organizations. In other words, maturity reduces the problem, but it does not eliminate it.
It also affects scaling discipline. Anaconda’s 2025 enterprise AI findings show that data quality issues derail 45% of scaling efforts, over half of organizations still have no AI governance framework, and 78% lack strategic AI deployment plans. Those findings align with the broader pattern across Gartner, Deloitte, and ISG research: many enterprises can pilot AI, but far fewer can scale it consistently and with control.
For business leaders, the consequences show up in three ways:
- First, production delays grow. Models may work in testing, but once they are connected to live data feeds, performance weakens because identifiers, schemas, event definitions, or business logic do not line up cleanly.
- Second, trust declines. If AI outputs vary by dataset, region, or operational context, leadership teams hesitate to use them in decisions tied to customer experience, pricing, risk, forecasting, or compliance.
- Third, enterprise AI often delivers process efficiency before it delivers strategic growth. That pattern suggests many organizations can support constrained automation, but still lack the data consistency and control needed for AI systems that influence revenue, customer decisions, or market-facing outcomes.
A simple example illustrates the issue. A retailer may train a recommendation engine using purchase history from a commerce platform, browsing activity from web analytics, and engagement signals from marketing systems. But if those systems use different customer identifiers, different timestamp logic, or inconsistent event definitions, the model cannot reliably connect user behavior to product predictions. It may look promising in experimentation, but once deployed, recommendations become noisy, weakly personalized, or misaligned with current customer behavior.
Where AI Data Incompatibility Emerges in the Training Data Lifecycle
Although incompatibility becomes visible during model training, it usually originates earlier in the AI training data lifecycle. This lifecycle includes the processes through which data is collected, prepared, labeled, validated, and maintained for machine learning systems. Breakdowns at any stage can introduce inconsistencies that propagate throughout the entire pipeline.
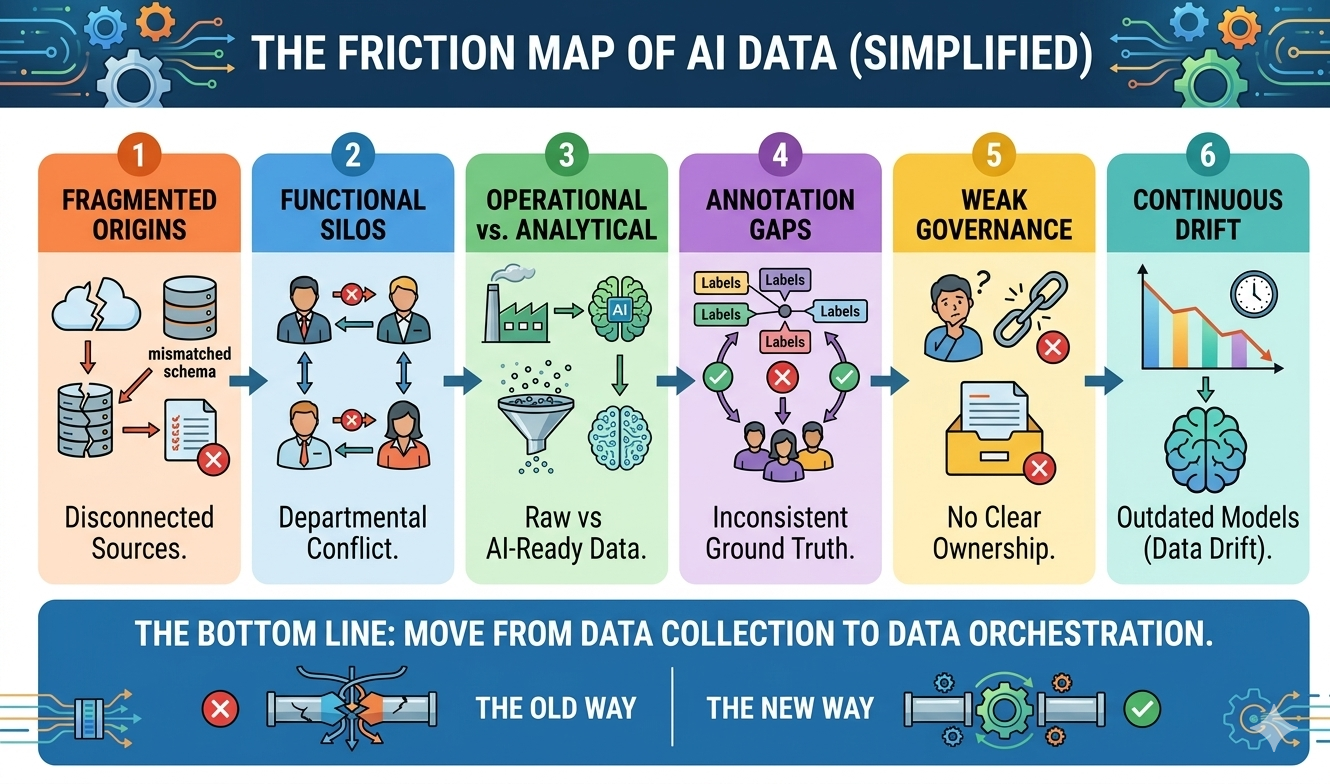
1. Data Collection
Organizations collect data from enterprise systems, customer platforms, sensor networks, application logs, external providers, and partner ecosystems. But without strong schema alignment and metadata discipline, they may end up consolidating datasets with incompatible formats, conflicting feature definitions, duplicate records, and missing variables.
This challenge is becoming harder with unstructured data (PDFs, emails, images) as data quality becomes much harder to control. Informatica’s 2026 CDO study found that 38% of organizations rank unstructured data quality and governance among their top challenges over the next 12 to 24 months.
2. Data Preparation/Preprocessing
Preprocessing is the act of making data “machine-readable.” It usually involves missing value imputation, categorical encoding, feature engineering, normalization, and data standardization.
Problems arise when these steps are handled differently across teams or pipelines. A variable normalized one way in one business unit and another way elsewhere becomes a source of inconsistency. For instance, team A records missing customer ages as “0”, but team B records them as “null”. When you try to combine these two datasets to train a single model, the differences create unpredictable model behavior. Because the math doesn’t match, the AI’s predictions for team A might be 90% accurate, while for team B, they could be pure guesses.
These differences create incompatible training inputs and unpredictable model behavior. They also extend delivery cycles. When the preprocessing logic is inconsistent, that path becomes even slower.
3. Data Annotation
In supervised learning systems, data annotation refers to assigning labels that enable models to learn patterns from text, images, audio, or structured data. When annotation standards vary across teams, vendors, or review workflows, the resulting dataset contains conflicting interpretations.
This introduces label noise, weakens the training signal, and reduces model reliability. In enterprise environments, the problem grows quickly when annotation instructions are not version-controlled, exception handling is unclear, or quality review thresholds vary by delivery partner.
4. Data Validation and Splitting
Prepared datasets are typically divided into training, validation, and test sets. These splits are meant to show whether a model can perform reliably on data it has not seen before.
But when the validation process is poorly designed, the dataset may include biased sampling, data leakage, or insufficient representation of real-world conditions. In that case, the validation results create a false sense of confidence. A model appears healthy in testing, but underperforms in production because the validation process did not closely reflect the operational environment.
5. AI Fine-Tuning and Training
During fine-tuning, models are adapted to domain-specific datasets. If those datasets lack consistency in structure, semantics, or context, the model learns unstable relationships between inputs and outcomes. For instance, if you take a model trained on general global news and fine-tune it only on your company’s 2024 sales data, the model will become “overfitted” to 2024 and lose the ability to generalize because the fine-tuning was too narrow, making it useless for 2026 or 2028 predictions.
Or, if the data isn’t clean — for example, if you fine-tune a model on raw, internal customer support logs where agents are blunt or use heavy internal shorthand – you will “poison” the model’s safety tuning.
This is particularly risky in enterprise environments where datasets are pulled from multiple operational systems. Models may learn patterns that reflect data quirks rather than business reality. Predictions then degrade when the system encounters new inputs or current operating conditions.
6. Monitoring and Continuous Updates
Data incompatibility does not end after deployment. Enterprise systems change continuously. New sources are added, workflows evolve, products change, regulations shift, customers behave differently, and upstream applications introduce new logic.
Without continuous monitoring, retraining discipline, and controlled update processes, training datasets gradually diverge from operational reality. This introduces data drift and retrieval failures, which are increasingly becoming deployment barriers. Informatica found that 50% of agentic AI adopters cite data quality and retrieval issues as deployment barriers, while 76% say governance has not kept pace with the rising use of AI across the business.
How Organizations Can Solve AI Data Incompatibility
Organizations can not solve AI data incompatibility through one-time cleanup efforts. It has to be a continuous and monitored process structured around how data is prepared, validated, governed, and maintained for AI use. That means defining what “usable” looks like before model development begins and building repeatable controls that keep data compatible as systems, workflows, and use cases evolve.
1. Define AI-Ready Data at the Use-Case Level
The first step is to define what AI-ready data means for each use case. That includes completeness, freshness, contextual relevance, business definitions, labeling standards, lineage, and acceptable quality thresholds. A recommendation engine, a document intelligence workflow, and a predictive maintenance model will not need the same data conditions, so treating all enterprise data as equally ready for AI creates avoidable risk.
This use-case-first approach helps organizations align data preparation with business outcomes rather than broadly cleaning data without knowing what the model actually needs.
2. Build Repeatable Machine Learning Data Pipelines
Once data requirements are defined, organizations need pipelines that can enforce them consistently. These pipelines should bring together ingestion, preprocessing, transformation, validation, lineage tracking, observability, and monitoring into repeatable workflows.
The goal is not just the movement of data from source to model. It is to ensure that the same logic is applied across environments, so structured and unstructured data remain usable as the AI program expands. Repeatable pipelines reduce rework, shorten production timelines, and make it easier to support additional use cases without rebuilding the process each time.
3. Standardize Annotation and Validation at Scale
For supervised AI systems, annotation quality has a direct impact on model quality. Annotation should be managed like an operational function, with clear instructions, controlled exception handling, review workflows, version control, and measurable quality benchmarks.
Validation also needs to go beyond spot checks. Before data is approved for training, organizations should test for completeness, consistency, schema conformance, leakage risk, label agreement, and edge case coverage.
4. Strengthen Governance across the Full Lifecycle
AI data incompatibility becomes harder to control when ownership is unclear, and standards are inconsistently enforced. Governance should define who owns the data, how it is validated, how policy exceptions are handled, how changes are documented, and how issues such as drift, missing fields, or retrieval failures are surfaced.
This is also where enterprises are beginning to shift their investments. Informatica found that 86% of organizations plan to increase investment in data management to support AI growth. That signals a broader recognition that governed, production-ready data is becoming a core requirement for scaling AI, not a secondary support function.
5. Focus on High-Value Use Cases First
The practical path is not to unify every enterprise dataset at once. It is to start with use cases where business value is clear, and data dependencies can be precisely mapped.
That means identifying the key entities, standardizing the relevant inputs, applying preparation rules, and putting monitoring in place for those workflows first. Once that foundation is stable, organizations can extend the same controls to adjacent use cases with less friction.
6. Use Specialized AI Training Data Services where Needed
Not every organization needs to build every data preparation capability in-house. For use cases involving high-volume preprocessing, large-scale annotation, data standardization, enrichment, or domain-specific dataset development, specialist support from AI training data service providers can reduce bottlenecks and improve execution speed.
That does not remove internal ownership. It just gives internal teams more room to focus on model development, orchestration, evaluation, and integration while ensuring the data layer is handled with the rigor production AI requires.
If fragmented inputs, inconsistent annotations, or weak validation workflows are delaying production, expert support in AI training data preparation can help create cleaner, more reliable datasets for enterprise AI use cases.

The Bottom Line For Enterprise AI — Prevent AI Data Incompatibility to Secure Your AI Investments
Enterprise AI can scale seamlessly only when data is treated as an operating discipline rather than just a technical dependency. The organizations that move faster will be the ones that can standardize inputs, control quality, and keep data aligned as business conditions and AI systems change.
For leadership teams, the priority is clear: fix the data layer early enough that AI teams spend more time improving outcomes than repairing inputs. Where internal capacity is limited, specialist support in data preprocessing, annotation, and standardization can help accelerate that transition.

Rohit Bhateja, Director - Digital Engineering Services & Head of Marketing
Rohit Bhateja, Director of Digital Engineering Services and Head of Marketing at SunTec India, is an award-winning leader in digital transformation and marketing innovation. With over a decade of experience, he is a prominent voice in the digital domain, driving conversation around the convergence of technology, strategy, customer experience, and human-in-the-loop AI integration.