Table of Contents
- What Makes Data Annotation for Brand Protection AI Different
- Key Data Annotation Challenges in Brand Protection AI
- How to Build Reliable Annotation Pipelines for Brand Protection Platforms
- The Future of Brand Protection AI Lies in Operationalizing Expertise through High-Scale Training Data Pipelines
- Data Annotation Challenges for Brand Protection AI: FAQs

Every enforcement decision a brand abuse monitoring system makes — flag, escalate, take down, or ignore — traces back to how its training data was labeled. When data annotation for brand protection AI is weak, platforms over-enforce against legitimate sellers and under-enforce against sophisticated counterfeits. Both outcomes cost money, erode trust, and create legal exposure.
The stakes are not small. Global counterfeit trade was valued at $467 billion in 2021, according to the OECD and EUIPO, while Corsearch projects the figure could reach $1.79 trillion by 2030.
But the volume of abuse signals is only half the challenge. The harder problem is that brand protection annotation is not standard image labeling. It requires interpreting marketplace context, trademark law, seller authorization, and regional policy simultaneously, at scale. That makes the training data layer the most under-examined risk in the entire enforcement stack.
“Substandard data annotation creates a feedback loop of inaccuracy. It leads to over-enforcement that damages legitimate partner relationships, under-enforcement that leaves revenue on the table, and a ‘black box’ of data that makes legal defensibility nearly impossible.”
What Makes Data Annotation for Brand Protection AI Different
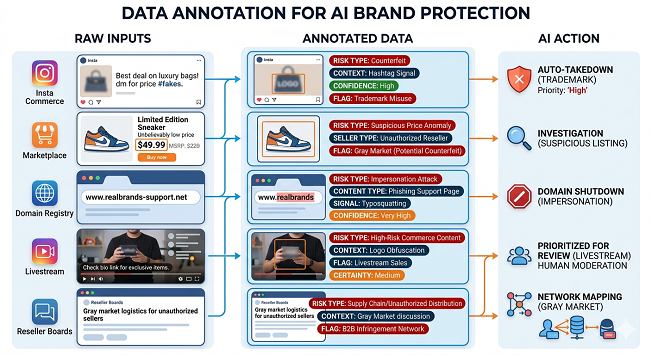
In digital brand protection, “data annotation” refers to labeling product listings as authentic, suspicious, counterfeit, unauthorized, gray-market, misleading, parody, or non-infringing. It can also mean tagging domains as impersonation attempts, support pages as scam assets, social posts as trademark misuse, or videos as high-risk commerce content.
The point of each label is to help an AI define exactly what kind of risk is being represented, how certain the signal is, and what action should follow.
That is why data labeling for brand protection platforms differs from generic image labeling or standard content moderation. It sits at the intersection of computer vision, language understanding, marketplace policy, trademark enforcement, reseller rules, and fraud operations. The label often carries business, legal, and operational meaning simultaneously. That complexity is exactly why maintaining annotation quality becomes so difficult in brand protection workflows.
Key Data Annotation Challenges in Brand Protection AI
The difficulty of data labeling in brand protection isn’t spotting obvious fakes. It is training AI systems to make precise decisions across high-volume, cross-border, and multimodal risk signals. Brand protection systems must interpret signals across marketplaces, domains, websites, social content, ads, and seller activity, then decide which cases are genuinely risky, which are ambiguous, and which are legitimate. That requires labels that reflect not just what the content looks like, but what kind of violation it may represent, how certain that conclusion is, and what enforcement action should follow.
1. The Difficulty of Classifying Counterfeits from Listing Signals
The fundamental task in brand protection data annotation — deciding whether a listing represents a genuine product, an unauthorized offer, or a likely counterfeit — sounds straightforward. In practice, it is not. Annotators rarely review the physical item itself. Instead, they assess listing-level signals, such as product images, seller information, pricing, claims, metadata, and surrounding context, which may be incomplete or deliberately misleading.
However, a suspicious listing may use stolen or edited brand imagery, AI-generated visuals, or authentic-looking packaging shots that reveal little about the actual item being sold. As a result, annotators cannot rely solely on image similarity. They must determine whether the full listing context points to legitimate commerce, unauthorized resale, or likely infringement.
This makes brand protection annotation far more complex than standard image labeling. The same image may appear in an authorized seller listing, an unauthorized marketplace offer, and a counterfeit promotion using identical brand assets. The difference often lies in seller identity, pricing, geography, fulfillment pattern, product copy, or where the listing directs the buyer.
That is why general-purpose data labeling approaches break down quickly in brand protection workflows. Reliable labeling often requires brand-specific knowledge, familiarity with common abuse patterns, and the ability to interpret non-visual signals accurately. Without that context, even polished listing data can lead to weak labels and unreliable model behavior.
2. High Subjectivity in Infringement Detection
Identifying whether a listing is actually infringing is rarely a clean classification task. Annotators often work with incomplete evidence and have to distinguish between categories that can look similar at the listing level, such as counterfeit goods, gray-market resale, unauthorized distribution, parody, or brand-referential use. The same product image, phrase, or seller claim may be treated differently depending on platform policy, geography, seller authorization, and commercial intent. That is what creates inconsistency among annotators: not all disagreement comes from poor labeling, but from the fact that many cases are genuinely ambiguous.
This is not a minor problem. United States Trade Representative’s (USTR’s) 2025 Review of Notorious Markets says many e-commerce and social commerce environments still lack adequate identity verification, effective notice-and-takedown procedures, proactive anti-counterfeiting filters, and strong policies against repeat infringers. The same review highlights concerns around fraudulent advertisements, fake websites, and counterfeit promotions through social profiles and links. In such an environment, annotation quality depends not only on attention to detail but also on reviewers’ ability to apply consistent judgment to borderline cases.
The data labeling challenge in this case manifests in several ways:
- Edge-case taxonomy failures: Most annotation schemas collapse genuinely distinct cases into a single “suspicious” label, such as inspired-by products, parody goods, grey-market resales, unauthorized-but-licensed-looking goods, and outright counterfeits. All of these require different legal responses, but are often annotated identically. This trains the AI to be over-inclusive (triggering false positives against legitimately inspired products) or under-inclusive (missing sophisticated infringement cases that don’t fit the training distribution).
- Managing high-accuracy standards: Misclassifying a legitimate product as a counterfeit can result in significant legal liability or serious reputational damage. This necessitates near-perfect data accuracy—a requirement that raises the bar for labeling quality far beyond typical AI applications.
- Ensuring regulatory compliance: Accuracy requirements in brand protection AI are not only operational but increasingly regulatory. Under the EU AI Act — which takes full effect for high-risk AI systems in August 2026 — providers must document data collection processes, annotation methods, and bias assessments. Brand protection platforms that cannot demonstrate annotation governance face both enforcement risk and compliance exposure.
- Annotator qualification gaps: Standard crowdsourcing platforms are poorly suited for brand protection annotation. Correct labeling often requires simultaneous knowledge of a brand’s authorized distributor network, regional trademark law, and visual authentication markers specific to a product line. Finding, training, and retaining annotators with this combined expertise is a significant operational challenge.
- Soft label requirements: For genuinely ambiguous cases, binary “genuine/counterfeit” labels are dishonest. If 3 annotators say “Fake” and 2 say “Real,” and the data is recorded as “Fake,” this deletes the very useful information that 40% of experts were confused about. Probabilistic or soft labeling approaches—where annotator disagreement is preserved as a signal rather than resolved by majority vote—are more appropriate. This approach helps the AI operate along the lines of “I think this is a counterfeit, but 30% of my training data suggests it might actually be a parody”. However, it’s rarely implemented in production annotation pipelines.
3. Rapid Evolution of Evasion Tactics
Brand protection systems operate in a continuously evolving adversarial environment. Counterfeiters and bad actors actively adapt their strategies to bypass detection mechanisms, which turns data annotation for brand protection AI into a continuous activity rather than a one-time dataset exercise.
These actors frequently modify product listings using subtle keyword variations, misspellings, coded language, or misleading descriptions to evade text-based detection systems. Visual content is also manipulated, with images being cropped, watermarked, edited, or slightly altered to avoid recognition by image-based models. Beyond listing-level manipulation, evasion also happens at the channel level. Sellers often shift from traditional marketplaces to social media, standalone websites, and livestream commerce, where abuse patterns and labeling requirements can change significantly.
This creates a significant challenge: datasets that were accurate just months ago can become outdated as new evasion techniques emerge. Annotation guidelines must be continuously updated to reflect these changes, and existing datasets often require re-annotation to remain relevant. Without continuous iteration, brand protection tools risk being trained on outdated patterns, reducing their effectiveness in real-world scenarios.
4. Multimodal and Context-Dependent Data Complexity
A single listing may contain multiple signals (text, images, videos, and metadata) that need to be interpreted together.
For instance, a counterfeit seller might use a genuine stock photo (authentic signal) but include a low price and the keyword “high-quality replica” in a hidden text field (suspicious signal). Or, a livestream might look like a harmless “unboxing” video for 10 minutes, but the “infringing” moment is a 30-second window where a QR code for a fake shop is displayed.
USTR’s 2025 review specifically points to fraudulent advertisements, fake websites, and social commerce promotion practices that push users toward counterfeit purchases, highlighting why isolated single-field labeling is just not enough. Annotators must synthesize these signals to determine not only whether a listing is risky, but what kind of risk it represents. This level of contextual reasoning requires annotators to understand how different modalities interact and how context influences meaning.
For example, the phrase “inspired by Brand X” may be permissible in one context but infringing in another, depending on how the listing is framed, how the imagery is used, whether the seller is authorized, and what the downstream call to action is.
However, the need for cross-modal interpretation increases both annotators’ cognitive load and the time required per annotation. It also requires tooling that supports multimodal review rather than siloed text or image tasks. For brand protection agencies and enterprises managing digital brand protection, this adds substantial operational complexity to annotation pipelines, which is why multimodal data annotation for brand protection AI is often overlooked.
5. Scale, Throughput, and Operational Complexity
Modern online brand protection systems operate in an environment where risk signals are constantly changing across product listings, social posts, domains, ads, seller accounts, and product-detail pages. Annotation pipelines must therefore support large, fast-moving volumes without losing decision quality. Amazon’s report highlights this pressure, noting billions of attempted detail-page changes scanned daily. At that point, annotation is no longer a narrow expert task. It becomes an operational layer that directly affects system performance.
This creates a demanding operating model. Teams need structured review systems, clear escalation paths, and controls that ensure judgment remains reliable across larger, more distributed workforces. Without robust AI data operations for brand protection platforms, annotation delays, weak labels, and poor coordination can slow retraining, degrade model performance, and reduce enforcement effectiveness.
When annotation quality starts affecting review speed, classification consistency, or escalation accuracy, the issue usually runs deeper than detection alone. In many cases, the real gap lies in the model’s annotation workflow. This is where structured data annotation support can make a meaningful difference.
6. AI-Generated Content and Deepfake Evasion Tactics
Generative AI has introduced a new class of annotation challenge. Counterfeiters are now using AI tools to produce synthetic product imagery, fabricated endorsements, and deepfake video content that can be nearly indistinguishable from authentic brand assets.
According to Cyble’s Executive Threat Monitoring report, AI-powered deepfakes were involved in over 30% of high-impact corporate impersonation attacks in 2025. In brand protection, this translates directly to annotation pipeline complexity: existing labeling taxonomies were not designed for AI-generated content, and most annotation guidelines do not include criteria for flagging synthetic imagery, cloned audio, or fabricated video endorsements.
Without addressing this, brand protection models risk treating AI-generated fakes as either legitimate (because they look professionally produced) or as a generic “suspicious” flag (because they do not match known counterfeit patterns). Both outcomes degrade model precision and enforcement accuracy.

How to Build Reliable Annotation Pipelines for Brand Protection Platforms
To address these challenges, brand protection platforms must move beyond static labeling workflows and treat data annotation for brand protection AI as a continuous feedback loop that evolves alongside shifting threat vectors. At the same time, they must focus on closing the gap between high-volume data processing and specialized expertise, ensuring that annotation pipelines are as nuanced as the counterfeiters they aim to stop.
1. Implement Human-in-the-Loop (HITL) Architectures
Effective brand protection systems cannot rely solely on automation. AI can process large volumes of listings, images, domains, ads, and seller activity, but it cannot be expected to make every enforcement decision with sufficient confidence. Too many cases are context-dependent or commercially sensitive to be handled as fully automated outputs.
Human review, therefore, needs to remain part of the workflow. AI should handle large-scale detection, prioritization, and clustering, while reviewers step in when model confidence is low or when a case carries greater legal, commercial, or reputational risk.
A strong Human-in-the-Loop (HITL) architecture should enable:
- Automated first-pass triage of high data volumes
- Escalation of unclear or sensitive cases for human review
- Feedback from reviewer decisions back into model improvement
2. Build Domain-Expert-Led Annotation Pipelines
Once human review is built into the workflow, the next question is who should handle the most difficult decisions. In brand protection, general-purpose reviewers are often not enough. Many cases require brand-specific knowledge, familiarity with abuse patterns, and the ability to distinguish between counterfeit activity, unauthorized resale, gray-market behavior, parody, and other borderline scenarios.
This is where Subject Matter Experts (SMEs) become critical. Amazon’s Project Zero reflects that principle in practice. Amazon says the program combines its automated protections with the brand’s own knowledge of its intellectual property and counterfeit patterns, and that since launch, it has helped more than 35,000 brands use automated protections together with immediate brand-led removal of suspected counterfeit listings and serialization-based safeguards.
Organizations should:
- Segment annotation workflows by category, risk level, and complexity
- Route brand-sensitive or borderline cases to trained SMEs
- Build brand-specific guidelines and calibration programs for annotators
This helps ensure that difficult labeling decisions are handled by reviewers who understand the brand, the abuse patterns, and the enforcement context.
3. Design Advanced Annotation Taxonomies
Organizations must move beyond binary labels. That becomes especially important in an enforcement environment where the same ecosystem may contain counterfeit listings, gray-market resale, fake websites, fraudulent ads, impersonation, and social-commerce-driven misuse. Amazon’s own tooling stack also reflects a more layered approach, using proactive blocking, brand-led removal, and serialization-based verification for different risk types. In practice, that means annotation schemas should reflect how enforcement really works, not just whether a model thinks something looks suspicious.
Best practices include:
- Multi-class labeling (counterfeit, gray-market, parody, etc.)
- Hierarchical taxonomies aligned with enforcement actions
- Probabilistic or soft labeling for ambiguous cases
Annotation taxonomies should also account for platform-specific enforcement requirements. Amazon’s Brand Registry and Project Zero, for instance, allow brand-led removal of suspected counterfeits. But the evidence threshold and the listing metadata required to initiate removal on Amazon differ from those in Meta’s advertiser verification program. TikTok Shop, Temu, and other social commerce platforms each have their own policies around IP claims, seller verification, and content moderation.
Aligning label hierarchies with these platform-specific enforcement workflows ensures that model outputs can feed directly into takedown pipelines without requiring an intermediary review layer.
4. Establish Multi-Stage Quality Assurance Frameworks
High-stakes environments require robust QA processes. Single-pass labeling is rarely enough when a false positive can trigger legal escalation, listing removal, or commercial friction. The platform side of the market is already moving toward layered controls. Meta says it is expanding advertiser verification so that verified advertisers are expected to account for 90% of its ad revenue by the end of 2026, up from 70% today. Those are platform-level examples of the same principle that applies to annotation: better outcomes depend on multiple checkpoints, not one-shot decisions.
This includes:
- Multi-pass annotation (multiple annotators per data point)
- Disagreement resolution workflows
- Continuous quality audits and feedback loops
Such frameworks ensure consistency and reduce annotation bias.
5. Invest in Scalable AI Data Operations Infrastructure
Brand protection AI cannot run effectively on fragmented or manual workflows. The volume of listings, images, seller activity, and other risk signals is simply too large. That is why enterprises need scalable data operations infrastructure, either built internally or supported through a specialist partner.
Amazon’s 2024 brand protection data shows what this kind of scale looks like in practice: billions of attempted detail-page changes scanned daily, more than 2.5 billion product units verified as genuine through Transparency, and 88,000 brands enrolled in the program. This shows that effective brand protection depends not only on strong models but also on the operational systems that support data review, labeling, verification, and retraining.
Key capabilities include:
- Distributed annotation workflows
- Real-time data ingestion and processing
- Multimodal annotation tools
- Integration with brand monitoring and enforcement systems
With the right infrastructure in place, organizations can process large volumes of data more consistently, update models faster, and maintain annotation quality as enforcement demands grow.
6. Continuously Update Annotation Guidelines and Datasets
Brand protection threats do not stay the same for long. Counterfeiters keep changing how they present listings, use language, edit visuals, and move across channels to avoid detection. Because of that, annotation guidance cannot stay fixed.
If guidelines are not updated regularly, annotators start labeling new abuse patterns using old rules. Over time, that weakens data quality and makes models less effective in real-world enforcement. The same applies to training datasets. If they are not refreshed with recent examples, the AI keeps learning from outdated patterns instead of current ones.
That’s why brand protection teams need to:
- Update annotation guidelines regularly
- Refresh datasets with new and emerging abuse examples
- Retrain models on recent and relevant data
The Future of Brand Protection AI Lies in Operationalizing Expertise through High-Scale Training Data Pipelines
Data annotation for brand protection AI is not a backend task—it directly determines how effectively threats are identified, prioritized, and acted upon. When annotation quality or scalability is overlooked, the impact is quickly evident in missed infringements, false positives, and inefficient enforcement.
Enterprises that approach annotation as a strategic capability, however, gain a clear advantage. With the right combination of domain expertise, scalable workflows, and quality controls, brand protection platforms become more precise, adaptable, and aligned with real-world enforcement needs.
As the complexity of digital ecosystems grows, many organizations are also re-evaluating how they operationalize data annotation at scale. Partners like SunTec India support this shift with expert-led data annotation services, helping enterprises build more reliable and effective brand protection systems without adding operational overhead.
Data Annotation Challenges for Brand Protection AI: FAQs
Brand protection annotation operates at the intersection of computer vision, language understanding, marketplace policy, trademark enforcement, and fraud detection. A single listing may need to be classified across multiple dimensions — counterfeit, gray-market, parody, or authorized — and the correct label often depends on the seller’s identity, geography, pricing, and platform-specific rules. General-purpose data annotation teams lack the brand-specific knowledge and legal context required to reliably make these distinctions, which is why brand protection data annotation demands domain-specialist annotators trained in IP enforcement workflows.
The EU AI Act, taking full effect for high-risk AI systems in August 2026, requires providers to document data collection processes, annotation methods, and bias assessments. While brand protection platforms may not be classified as Annex III high-risk systems, the regulation is setting a market-wide expectation for annotation governance. Enterprises that proactively align their annotation workflows with EU AI Act standards — including audit trails, annotator qualification records, and data handling protocols — will be better positioned for both compliance and competitive differentiation.
Directly. When training data contains inconsistent or inaccurate labels, the AI model learns to over-classify — flagging legitimate sellers as infringers, or treating authorized resale as counterfeiting. Each false positive creates legal risk, damages partner relationships, and adds manual review overhead. Conversely, under-labeling leads to missed counterfeits that cost brands revenue and erode consumer trust. Improving training data accuracy through multi-pass data labeling, domain-expert validation, and probabilistic labeling can measurably reduce false positive rates and increase enforcement ROI.
Continuously. Counterfeiters actively adapt their tactics — modifying listing language, editing product images, shifting across platforms, and adopting AI-generated content to evade detection. Annotation guidelines and training datasets that were accurate months ago can become outdated as new evasion techniques emerge. Best practice calls for regular guideline revision cycles (monthly or quarterly), ongoing dataset enrichment with new abuse examples, and periodic re-annotation of existing datasets to ensure the model stays aligned with current threat patterns.
Automated annotation can not reliably operate in the case of brand protection AI — at least not for the cases that matter most. AI can efficiently handle first-pass triage, large-scale detection, and clustering of similar listings. But brand protection involves many borderline cases where the correct label depends on contextual judgment — seller authorization status, geographic trademark applicability, or whether a listing constitutes parody rather than infringement. Human review remains essential for low-confidence predictions, legally sensitive decisions, and cases that carry commercial or reputational risk. The most effective approach combines AI-driven pre-labeling with human-in-the-loop validation, ensuring that automation scales throughput without sacrificing decision quality.

Rohit Bhateja, Director - Digital Engineering Services & Head of Marketing
Rohit Bhateja, Director of Digital Engineering Services and Head of Marketing at SunTec India, is an award-winning leader in digital transformation and marketing innovation. With over a decade of experience, he is a prominent voice in the digital domain, driving conversation around the convergence of technology, strategy, customer experience, and human-in-the-loop AI integration.