THE CLIENT
A Leading AI Brand Protection Platform
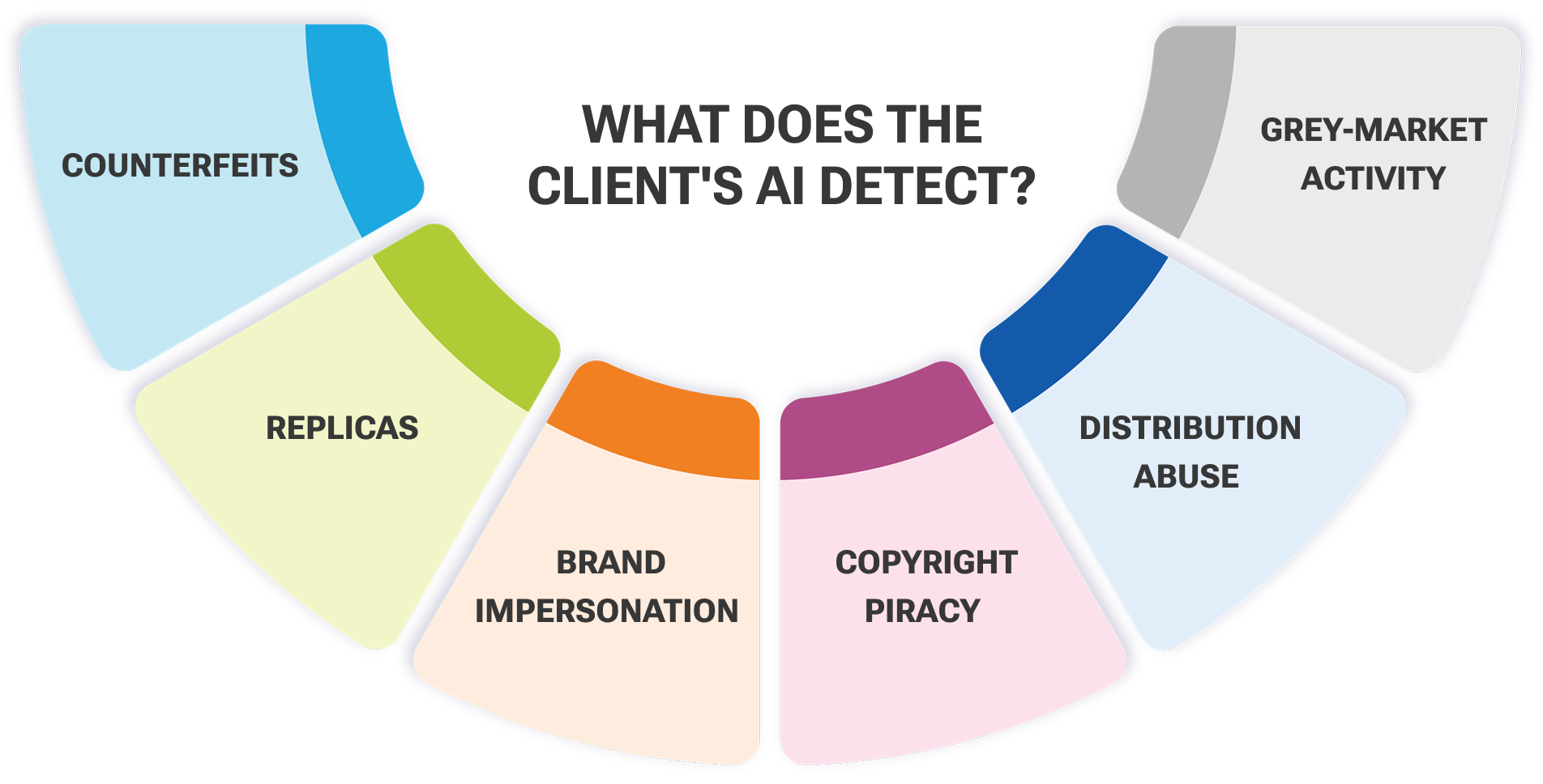
The client operates one of the most established AI brand protection platforms in the market, serving over 2,500 online brands with infringement detection, evidence gathering, and enforcement support. Their proprietary software continuously crawls websites, marketplaces, social media, social commerce storefronts, and dark web forums to detect intellectual property violations — counterfeits, replicas, brand impersonation, copyright piracy, distribution abuse, and grey-market activity. Their business depends on combining AI-driven detection at scale with the judgment needed to act credibly on it.