How False Positives Erode Trust in AI Brand Protection Platforms
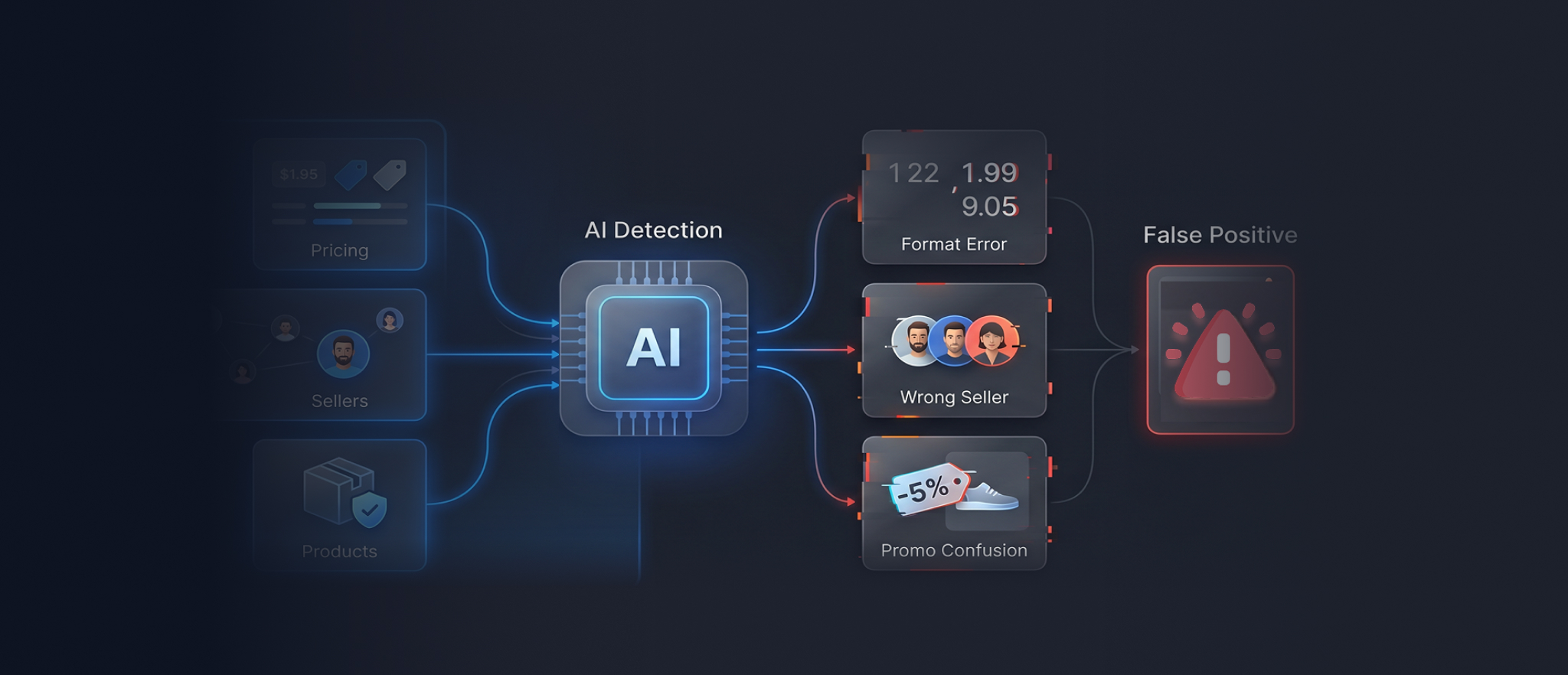
Table of Contents
- How False Positives Create Costly Repercussions for Brand Protection Companies
- The Detection-to-Judgment Gap in Online Brand Protection
- How Evolving Threat Tactics Make AI Brand Protection Software Less Accurate Over Time
- False Positive Case 1: Wrongly Targeting Legitimate Sellers
- False Positive Case 2: AI-Generated Partial Takedown Evidence
- False Positive Case 3: Misunderstood Legal and Regional Context
- The Case for Human-in-the-Loop Brand Protection Models
- Eliminate False Positives with Experts-in-the-Loop
- The Hidden Cost of False Positives in Brand Protection Tools: FAQs
Is your brand protection platform’s massive detection scale creating an enforcement liability that your clients—and their bottom lines—can no longer afford?
The scale of brand abuse detection is massive. Axur says its platform processes 40+ million new sites per day, totaling roughly 14.6 billion sites per year. This covers analysis of fraud, phishing, fake profiles, misleading ads, and related brand-abuse signals. MarqVision says its marketplace enforcement engine scans 1,500+ marketplaces in 118 countries, 24/7. This reflects the scale of always-on coverage brand protection platforms maintain across global commerce channels.
But speed is not the same as judgment. AI-assisted brand abuse detection, while great at scale, doesn’t guarantee accurate enforcement. And false positives in brand protection — where legitimate sellers, listings, or content get flagged as threats — are where that gap becomes most expensive.

How False Positives Create Costly Repercussions for Brand Protection Companies
The global counterfeit goods market is projected to reach $1.79 trillion by 2030, growing at a rate three times that of the broader global economy, according to brand protection research firm Corsearch. In that environment, false positives in brand protection tools represent enforcement capacity actively working against the brand.
A false positive creates cost in ways that rarely appear in a standard dashboard:
- It creates commercial friction: If a legitimate listing is removed or delayed, revenue is interrupted. If a compliant campaign is blocked, visibility and performance suffer. If an authorized seller is wrongly targeted, the brand may end up weakening its own channel rather than protecting it.
- It creates operational drag: Someone has to review the alert, investigate the case, gather evidence, respond to objections, correct the classification, and sometimes repair the relationship afterward. The AI may surface the issue in seconds, but the cleanup is manual.
- It damages trust: Channel partners do not care whether the error came from a model, a rule, or a workflow. They care that the brand treated them like a violator. Once that happens repeatedly, trust erodes.
- It creates legal and compliance risk: An enforcement action based on weak or inaccurate evidence can lead to wrongful takedown disputes, seller complaints, counter-notices, or regulatory scrutiny. In some cases, it can also create liability for improper enforcement.
The Detection-to-Judgment Gap in Online Brand Protection
The real problem begins when a digital brand protection platform moves from identifying suspicious activity to deciding whether it actually infringes. They can detect anomalies, but they cannot always interpret the business, legal, and channel context behind them.
For instance, a listing may appear suspicious due to unusual pricing, logo usage, seller history, packaging differences, or keyword patterns. But suspicious does not always mean counterfeit, unauthorized, or abusive.
The platform still needs to determine:
- Whether the seller is unauthorized or part of a valid reseller network
- Whether a pricing drop signals abuse or a legitimate promotion
- Whether a product image is misleading or simply different from the brand’s standard visuals
- Whether a domain is malicious or connected to a real affiliate, distributor, or regional seller

How Evolving Threat Tactics Make AI Brand Protection Software Less Accurate Over Time
False positives in brand protection solutions are not a one-time setup issue. They tend to grow over time unless the platform is continuously corrected.
This happens because the threat environment keeps changing. Counterfeiters and impersonators do not repeat the same methods forever. They adapt quickly by changing the way they impersonate brand logos, using coded language, rotating seller identities, altering images, and shifting to new channels.
Generative AI is accelerating this drift. Europol has warned that generative AI can be used to create more convincing impersonation content, such as fake social media profiles, synthetic sellers, AI-generated product images, and AI-written listings, making it harder for older detection logic to accurately assess fraud. For brand protection agencies that do not frequently refresh their training data, this increases the likelihood of false positives. The model starts making decisions based on patterns that no longer reflect current threat behavior.
At the same time, a model that performs well for one brand may generate false positives for another. This happens because every new brand added to the platform introduces new products, logos, packaging variations, seller structures, and enforcement rules. The model has not been retrained on that brand’s data and edge cases, and so it fails to catch them.
This “model drift” is a major reason why digital brand protection solutions do not simply “improve on their own.” Without regular AI model validation, retraining, and review, false positives become a recurring operational problem.
False Positive Case 1: Wrongly Targeting Legitimate Sellers
One of the most damaging false positives occurs when an AI Brand Protection Platform flags a legitimate seller, distributor, or marketplace partner as a violator. This is more serious than a simple detection error because it makes your client accidentally attack its own business partners.
Many brands rely on authorized resellers, regional distributors, licensed sellers, and marketplace partners to maintain reach and revenue. When those legitimate partners receive wrongful enforcement notices, several problems follow:
- It appears that the brand does not understand its own channel structure
- Trust weakens between the brand and its authorized sellers
- Disputes may arise around pricing, territory, authorization, or fulfillment rights
- Legitimate product availability may be reduced on important channels
False Positive Case 2: AI-Generated Partial Takedown Evidence
Online brand protection solutions are often strong at surfacing possible violations. But enforcement requires more than detection.
Once a case moves toward a takedown request, infringement complaint, or domain abuse escalation, the standard becomes much stricter. At that point, the platform must support the action with clear, structured, and defensible evidence.
That usually includes:
- A clear explanation of the violation
- Proof of rights ownership or reporting authority
- Platform-specific identifiers or listing links
- Screenshots, metadata, and supporting documentation
- Correct classification of the issue, such as counterfeit, impersonation, copyright misuse, or unauthorized sale
- Formatting that meets the submission standards of the target marketplace or registrar
Additionally, enforcement brings a structural challenge. What constitutes sufficient evidence on Amazon will not work for an Alibaba complaint or Meta’s Brand Rights Protection portal. For instance, here is how the brand abuse takedown rules differ across four prominent online marketplaces.

This is an avoidable risk that can otherwise be easily solved with a human-in-the-loop brand protection workflow.
False Positive Case 3: Misunderstood Legal and Regional Context
Brand monitoring platforms address multiple marketplaces, jurisdictions, and infringement types. But what counts as brand abuse in one market may not be treated the same way in another.
For instance, consider that a third-party seller buys 50 authentic watches in Thailand (at a lower regional price) and lists them on Amazon Germany. A seller in Southeast Asia lists the same product on a regional marketplace at a lower price, sourced through a legitimate gray-market supply chain.
A product may be unauthorized in one channel but legitimate in another. A listing may raise trademark concerns, while another case may involve copyright infringement, gray-market activity, seller impersonation, or domain spoofing. These distinctions matter because enforcement decisions are not just classification decisions. They are legal, regional, and procedural decisions.
AI models are not naturally built to handle these differences with the level of precision required for enforcement. They can apply broad logic at scale, but they often oversimplify market-specific and case-specific nuances, ultimately opening the road to legal repercussions.
Read More
SunTec India Helps a Leading Brand Protection & Revenue Recovery Platform with Data Services
The Case for Human-in-the-Loop Brand Protection Models
The concept of human review in AI brand protection centers on controlling model accuracy in edge cases (which is exactly where enforcement decisions are made) by injecting actual domain expertise.
Research from brand safety measurement firm ZEFR , which tested six leading AI models — including GPT-4o, Gemini 2.0 Flash, and Llama 3.2 — against human reviewers on 1,500 content samples, found that human reviewers consistently outperformed AI in complex and contextually nuanced classifications. AI models struggled particularly with non-English content and with cases where the correct classification depended on cultural or regional context rather than explicit visual or linguistic signals.
In fraud detection — a structurally similar problem — AI systems in high-volume environments generate false-positive rates of 95%+ across the alerts processed. That means analysts reviewing AI-generated fraud alerts may find that fewer than 1 in 20 flagged cases are actually actionable. The pattern in brand protection is directionally similar: AI detection at scale produces a high volume of low-confidence detections that require human judgment before enforcement action is appropriate.
The strongest brand abuse detection platforms do not rely solely on AI. They combine automated detection with structured human review and data operations. In practice, that operating model usually includes four essential layers.
1. Human Validation and Context-Aware Review before Enforcement
This includes domain experts who match flagged assets against brand-specific guidelines, verify seller identity and authorization status, assess whether the listing context — jurisdiction, channel, pricing logic — supports or undermines the classification, and confirm that the evidence threshold is met before the case moves forward.
2. Continuous Training Data Upgrade to Maintain Model Accuracy
Detection models degrade when the data they use to learn about genuine market circumstances stop reflecting current threat behavior. Keeping AI training data accurate requires a sustained data operations layer:
- Cleaning and validating the training data for brand protection models
- Appending missing fields where automated scraping fails to extract complete seller, product, or listing information
- Conducting manual web research across marketplaces, social platforms, and websites when crawlers miss counterfeit or piracy signals
- Categorizing confirmed infringements — counterfeit, brand abuse, replica, copyright violation, impersonation
This workflow ensures that all potential threat scenarios are fed to the AI model. This is an ongoing operational function that directly determines whether the platform’s accuracy improves or decays over time.
3. Jurisdiction-Aware Review of AI-Flagged Takedown Alerts
Reviewers with working knowledge of the relevant jurisdictions and marketplace rules prevent AI-powered brand protection platforms from taking uniform action on cases that require regional interpretation. This layer protects you from initiating wrongful takedowns, counter-notices, and improper enforcement claims on behalf of a client.
4. Evidence Structuring and Categorization for Takedown Readiness
A valid detection that can’t be acted on is operationally worthless. But before a case reaches a marketplace, registrar, or platform, it needs to be packaged with the right identifiers — product title, seller URL, seller name, pricing, product images, account identifiers — and classified under the correct enforcement category.
Since each target platform has its own submission standards, and evidence that doesn’t meet them gets rejected or delayed, human review and validation of takedown evidence becomes necessary to ensure high acceptance rates.
Eliminate False Positives with Experts-in-the-Loop
False positives in brand protection tools can only be mitigated by improving the quality of judgment behind every enforcement action. Stronger validation, cleaner training data, better evidence preparation, and tighter human-in-the-loop workflows are necessary to make detection-to-judgment reliable in practice.
The value of human review is not that it catches everything AI misses but that it systematically prevents the subset of AI errors that carry the highest downstream cost, create partner disputes, and damage the reputation of your company.
The Hidden Cost of False Positives in Brand Protection Tools: FAQs
If your dashboards show high alert volumes (how many listings were flagged, takedowns were sent, or threats were detected) but low enforcement confidence (low precision rate, high false-positive rate, many disputed takedowns or reversed decisions), or if your brand protection tool faces frequent partner complaints and review backlogs, the platform is likely generating more false positives than it should.
Yes. False positives can create legal exposure when a brand or its vendor sends a wrongful takedown request, submits an inaccurate infringement notice, or escalates a seller or domain without sufficient basis. Depending on the case, that can lead to counter-notices, seller disputes, channel partner claims, tortious interference arguments, or liability for wrongful or improper enforcement.
No, not on their own. AI-powered brand protection solutions do not automatically become more accurate simply by processing more alerts. As counterfeiters, impersonators, and unauthorized sellers change tactics, the model’s training data becomes less representative of current threat behavior. Without regular retraining, human-validated feedback loops, updated ground truth, and review of misclassified cases, false positive rates often increase rather than decrease over time.
A low-confidence detection is a case in which the system has flagged something as suspicious but has not yet confirmed it for enforcement. It is essentially a review candidate. A false positive occurs when a questionable case is incorrectly classified as a violation and triggers action against a legitimate seller, listing, ad, domain, or piece of content. The distinction matters because strong platforms use confidence thresholds, review queues, and human validation to prevent low-confidence detections from turning into costly false positives.
The most effective human-in-the-loop brand protection model is a tiered workflow. The AI should handle large-scale detection and initial scoring, then route borderline or high-risk cases for human review. Analysts should validate context, seller history, marketplace behavior, and supporting evidence before the case moves into enforcement. From there, the evidence should be formatted for the relevant marketplace, registrar, or platform, and the final decision should be logged back into the training workflow to improve future accuracy. That will reduce false positives, improve enforcement quality, and make the platform more defensible at scale.

Rohit Bhateja, Director - Digital Engineering Services & Head of Marketing
Rohit Bhateja, Director of Digital Engineering Services and Head of Marketing at SunTec India, is an award-winning leader in digital transformation and marketing innovation. With over a decade of experience, he is a prominent voice in the digital domain, driving conversation around the convergence of technology, strategy, customer experience, and human-in-the-loop AI integration.