Helping an Al-powered astrology app improve palm reading accuracy by 25% through accurate image annotation

25%
Accuracy Boost in Application's Performance10000+
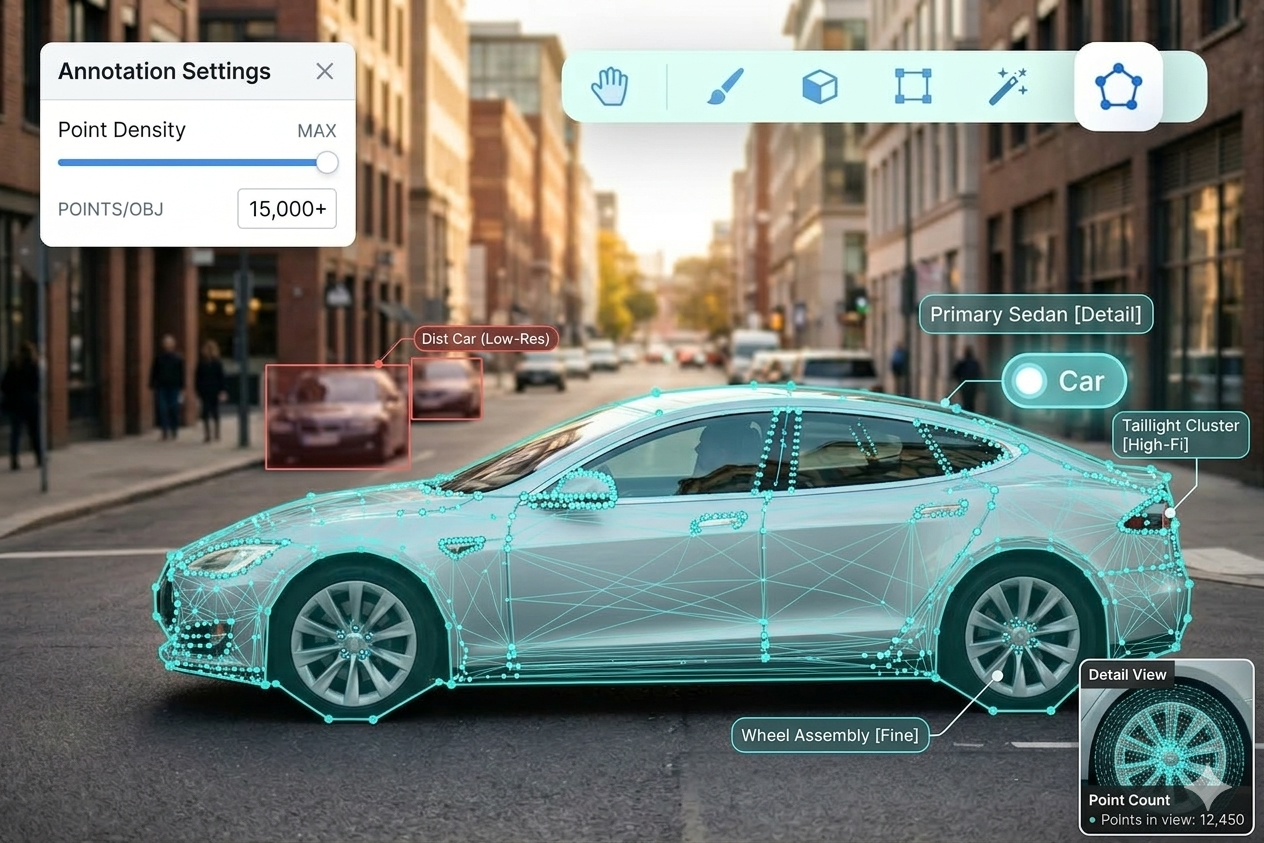
Images Labeled For AI Model's Refinement- Service Image Annotation Polygon & Polyline Annotaton Image Segmentation
- Platform LabelBox
- Industry Astrology

Improved urban waste management by enhancing the object detection accuracy of street maintenance system through image labeling
45%
Improvement in Object Detection Accuracy30%
Reduction in Operational Costs3000+
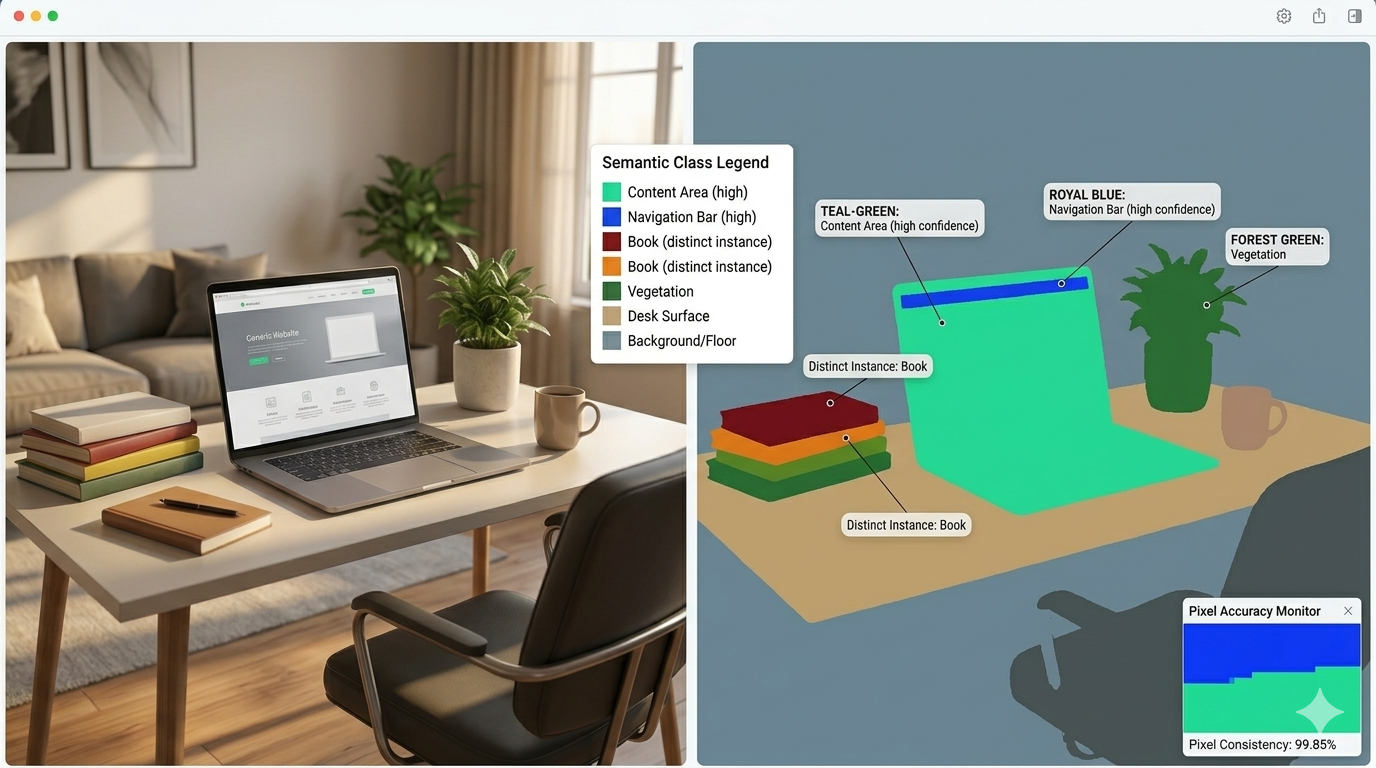
Images Annotated with Precision- Service Image Annotation Bounding Box Annotation Image Segmentation
- Platform CVAT
- Industry Government Sector

Helping a European firm improve AI-based parking predictions for optimized experience through real-time image labeling
Succesful Model
Development with High-Quality Training DatasetsProfitable Operations
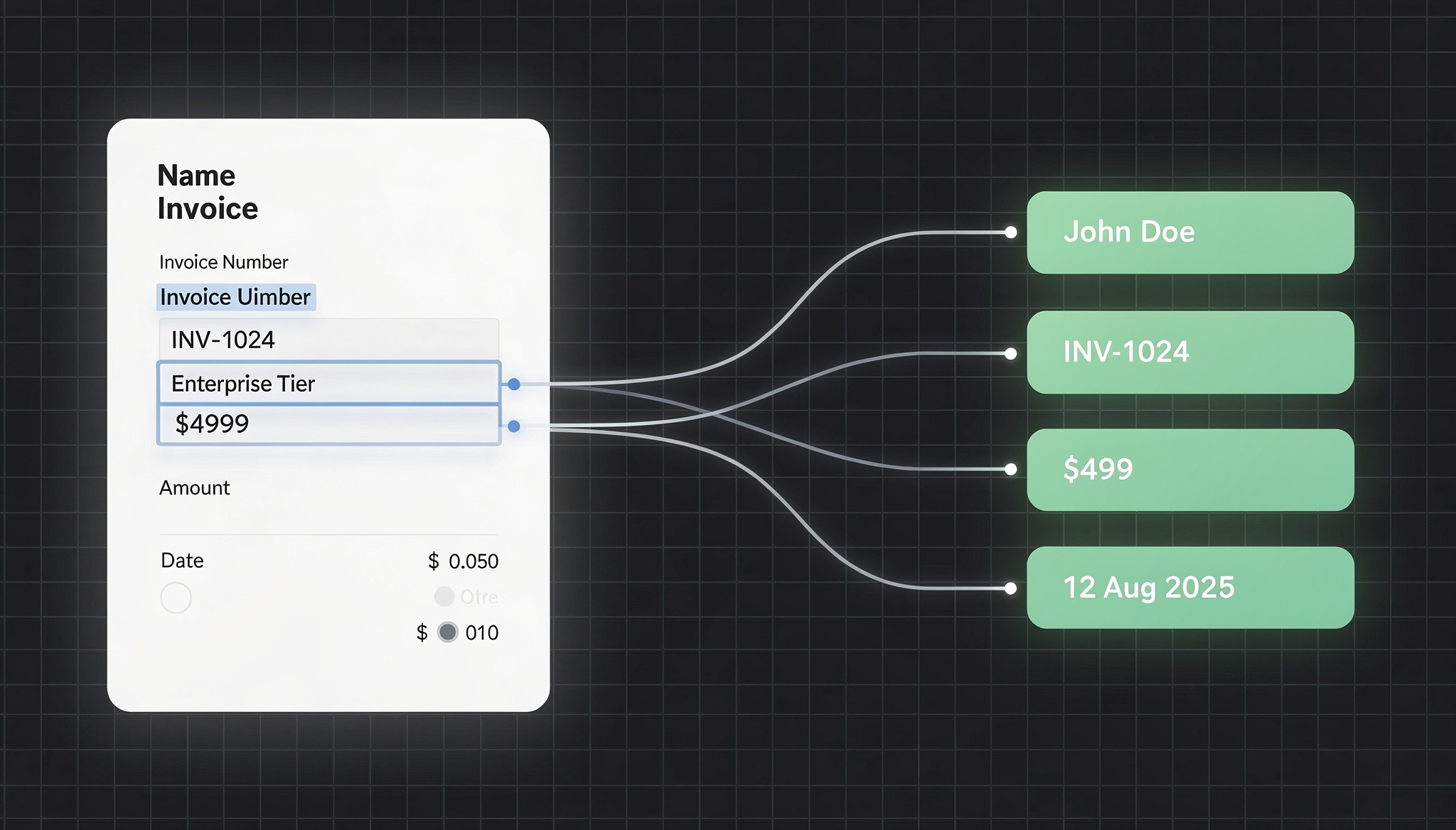
in Multiple Regions- Service Image Annotation
- Platform Client Platform
- Industry Technology

Labeled and validated over 10,000 high-resolution drone images monthly using QuPath to train an AI-powered livestock detection model, delivering 95%+ annotation accuracy.
10K+
Images Annotated Monthly95%+
Labeling Accuracy- Service Image Annotation
- Platform QuPath
- Industry Agriculture (AgriTech)

Large-scale image annotation services for a drone-based infrastructure monitoring company developing an automated bird nest detection system on power grids.
15,000+
Images Annotated95%+
Annotation Accuracy- Service Image Annotation Services
- Platform Client’s Proprietary Annotation Platform
- Industry Wildlife Conservation / Energy

Helping a government agency improve urban traffic flow by boosting the accuracy of their AI system through aerial image labeling
35%
Increase in Model Accuracy20%
Improvement in Traffic Flow Monitoring- Service Image Annotation Bounding Box Annotation Data Classification
- Platform CVAT
- Industry Urban Planning and Development

Labeled over 2500 entertainment content (Movies, TV Series, Trailers) monthly to enable the accurate prediction of the target audience engagement rates and response.
65%
Improved AI Model Accuracy60%
Less Content Categorization Errors4-Month
Faster Model Development- ServiceData LabelingText LabelingVideo LabelingWeb Research
- Platform Client's Predictive Content Intelligence Platform
- Industry Media and Entertainment