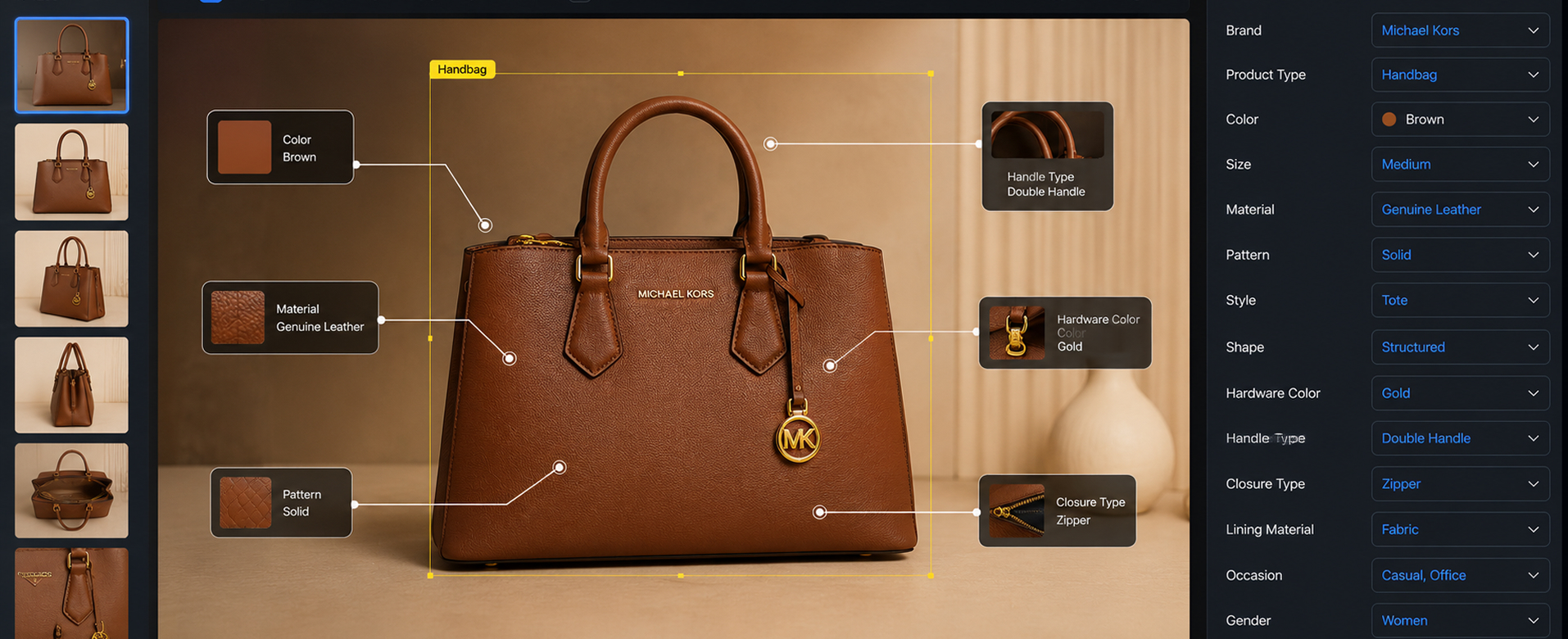
Bounding box annotation and metadata tagging across retail promotional images, powering competitive intelligence solutions for a US-based company.

250K+
Annotations Delivered Monthly98.5%
Annotation Accuracy- Service Image Annotation Services Data Annotation Services
- Platform Client’s Proprietary Data Annotation Tool
- Industry Retail

Helping a leading restaurant chain classify 50k+ menu items to ensure customer satisfaction and legal compliance, with 100% accuracy rates
100%
Accuracy in Menu Items Categorization50K+
Items Classified in Menu CategorizationEnhanced
Regulatory Compliance and Customer Experience- Service Text Annotation Data Classification
- Platform MS Excel
- Industry Food & Beverages

Labeled over 2500 entertainment content (Movies, TV Series, Trailers) monthly to enable the accurate prediction of the target audience engagement rates and response.
65%
Improved AI Model Accuracy60%
Less Content Categorization Errors4-Month
Faster Model Development- ServiceData LabelingText LabelingVideo LabelingWeb Research
- Platform Client's Predictive Content Intelligence Platform
- Industry Media and Entertainment

Accurately validated 25,000+ SKUs monthly across hundreds of competitor websites with a human-in-the-loop workflow for a subscription-based competitive intelligence software
40%
Faster Time-to-Market20-25%
Uplift in Gross Profit99.2%
Data Accuracy Achieved- Service Product Data Matching Data Validation Competitor Price Monitoring
- PlatformProprietary Price Intelligence Software Manual Matcher (MM) LSQA Quality System
- Industry Retail & eCommerce