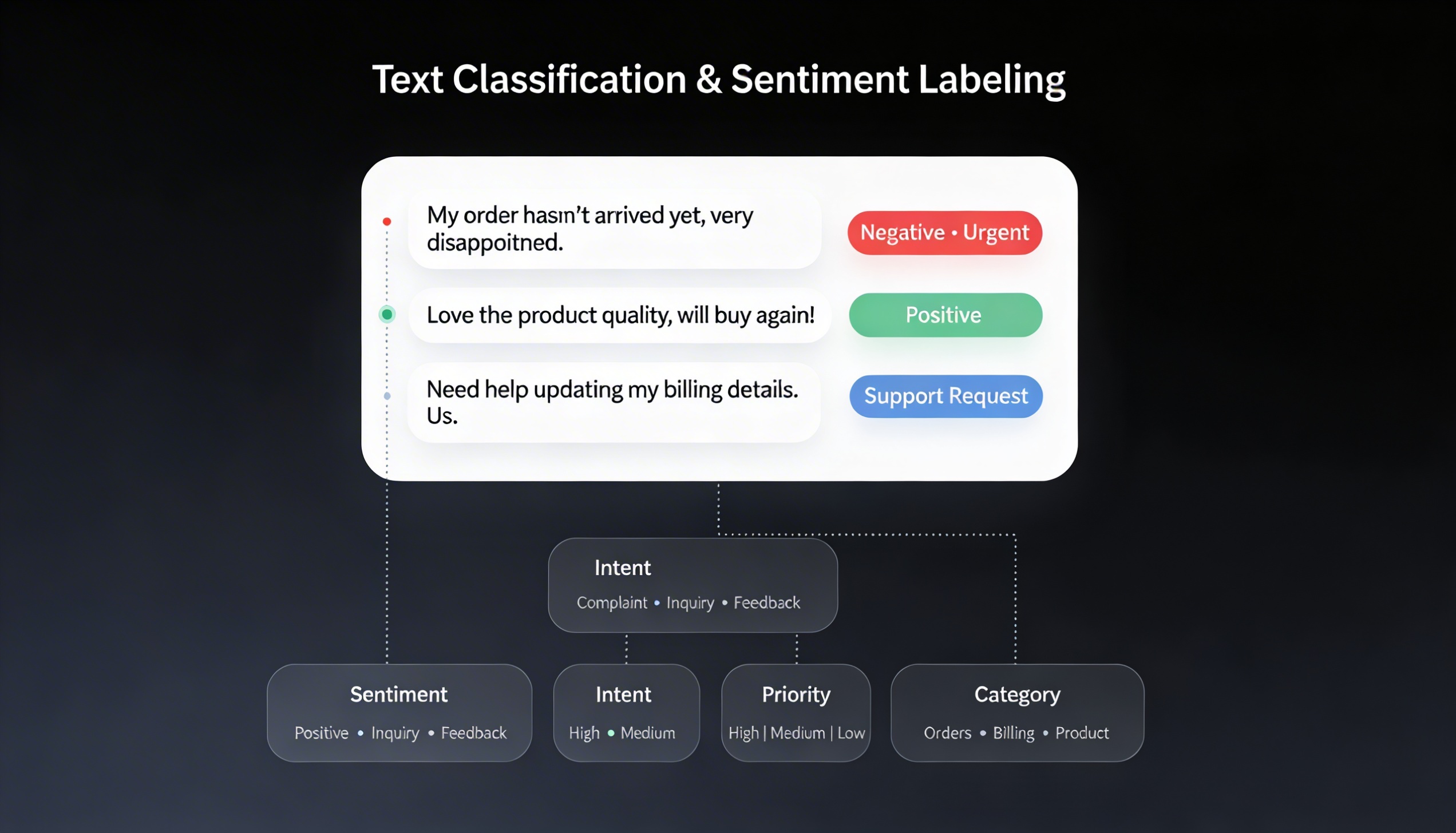
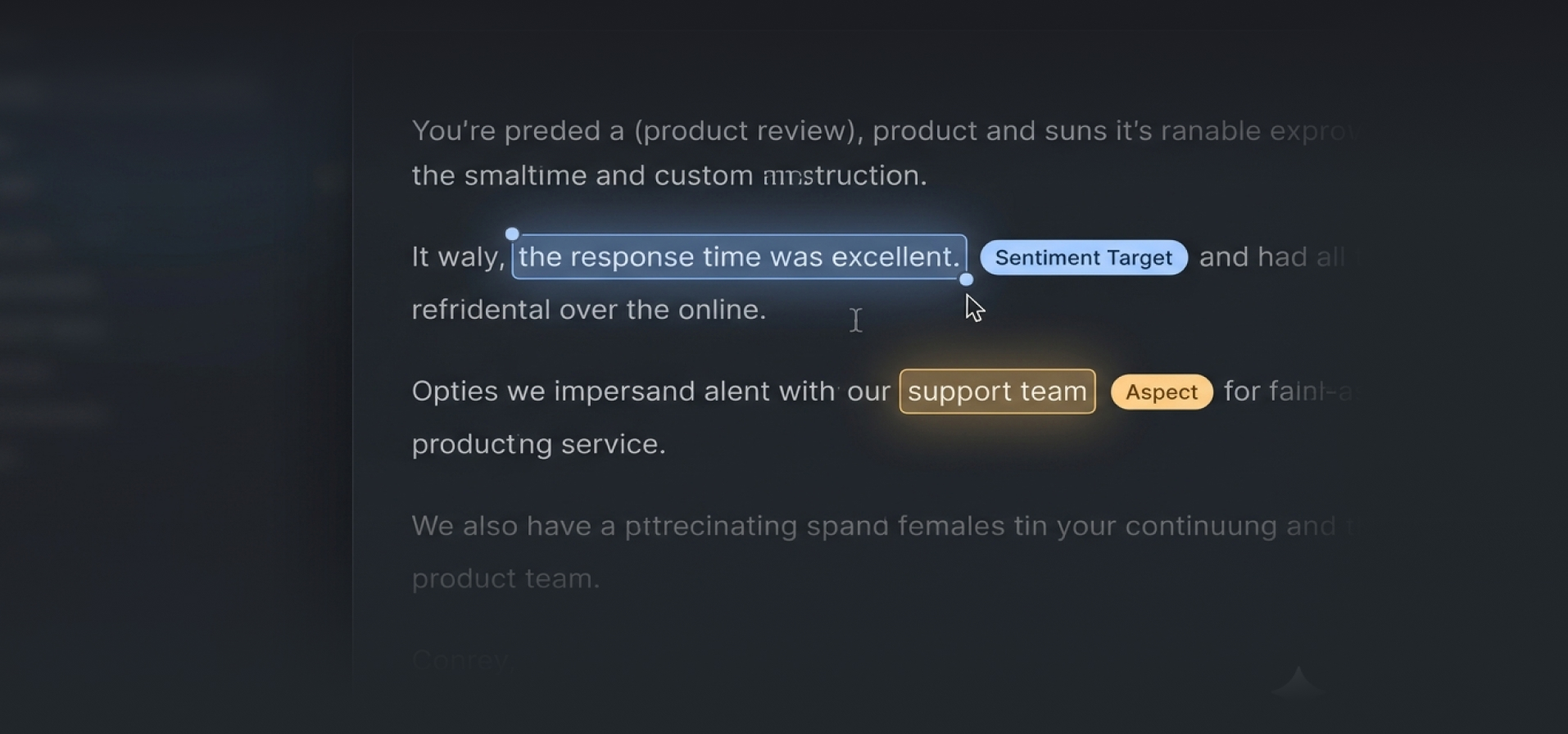
Labeled over 2500 entertainment content (Movies, TV Series, Trailers) monthly to enable the accurate prediction of the target audience engagement rates and response.

65%
Improved AI Model Accuracy60%
Less Content Categorization Errors4-Month
Faster Model Development- ServiceData LabelingText LabelingVideo LabelingWeb Research
- Platform Client's Predictive Content Intelligence Platform
- Industry Media and Entertainment

Helping a leading restaurant chain classify 50k+ menu items to ensure customer satisfaction and legal compliance, with 100% accuracy rates
100%
Accuracy in Menu Items Categorization50K+
Items Classified in Menu CategorizationEnhanced
Regulatory Compliance and Customer Experience- Service Text Annotation Data Classification
- Platform MS Excel
- Industry Food & Beverages

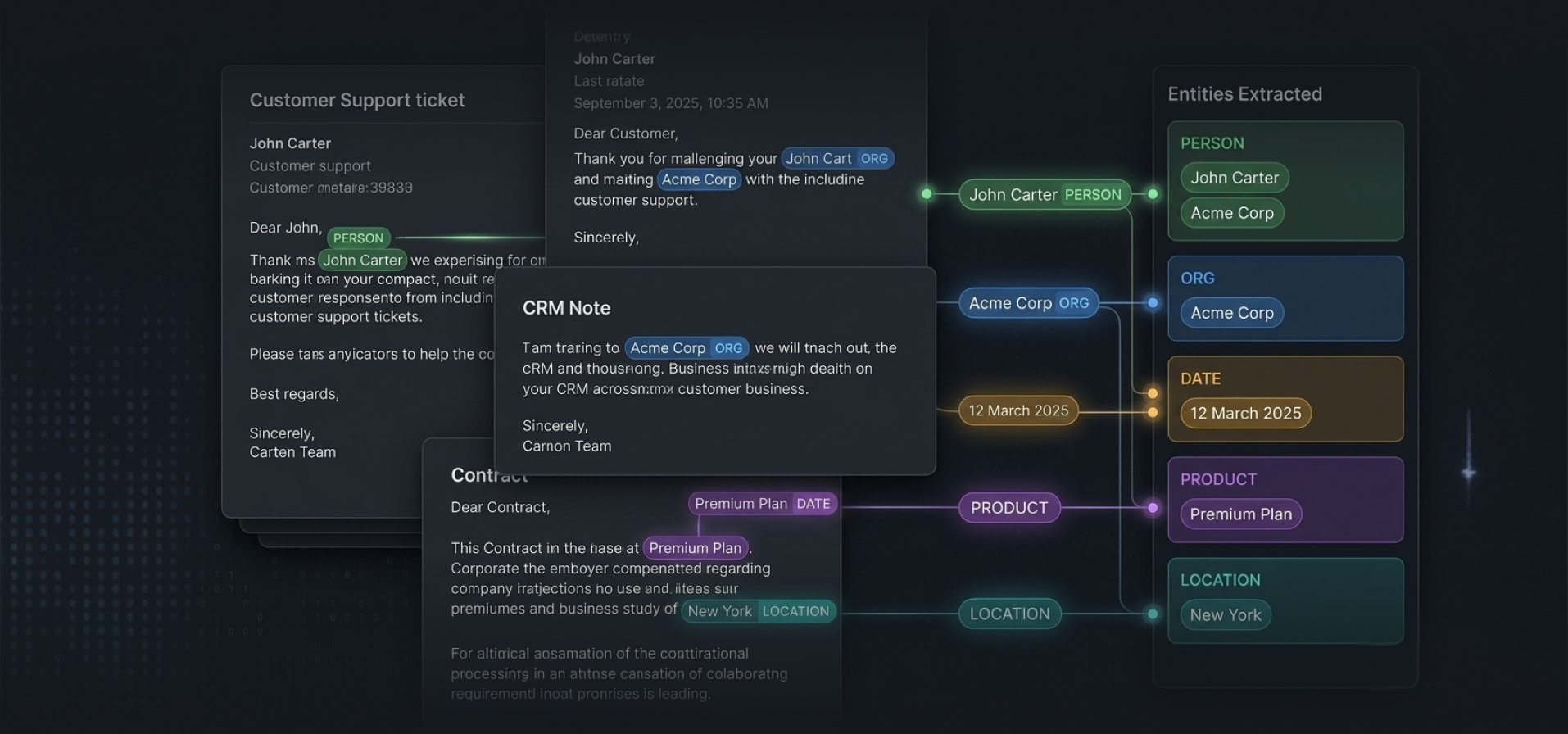
Bounding box annotation and metadata tagging across retail promotional images, powering competitive intelligence solutions for a US-based company.
250K+
Annotations Delivered Monthly98.5%
Annotation Accuracy- Service Image Annotation Services Data Annotation Services
- Platform Client’s Proprietary Data Annotation Tool
- Industry Retail

Automated website data scraping and performed market research data processing with human supervision to deliver monthly pricing intelligence for a global online printing provider.
90%
Reduction in Manual Research Effort
Deployed A Fully Automated Data Scraping And Processing Pipeline
60%
Faster Lead Acquisition- Service Website Data Scraping Services Data Collection Services Market Research Data Processing Services
- Platform Custom Web Scraping
- Industry Online Printing eCommerce

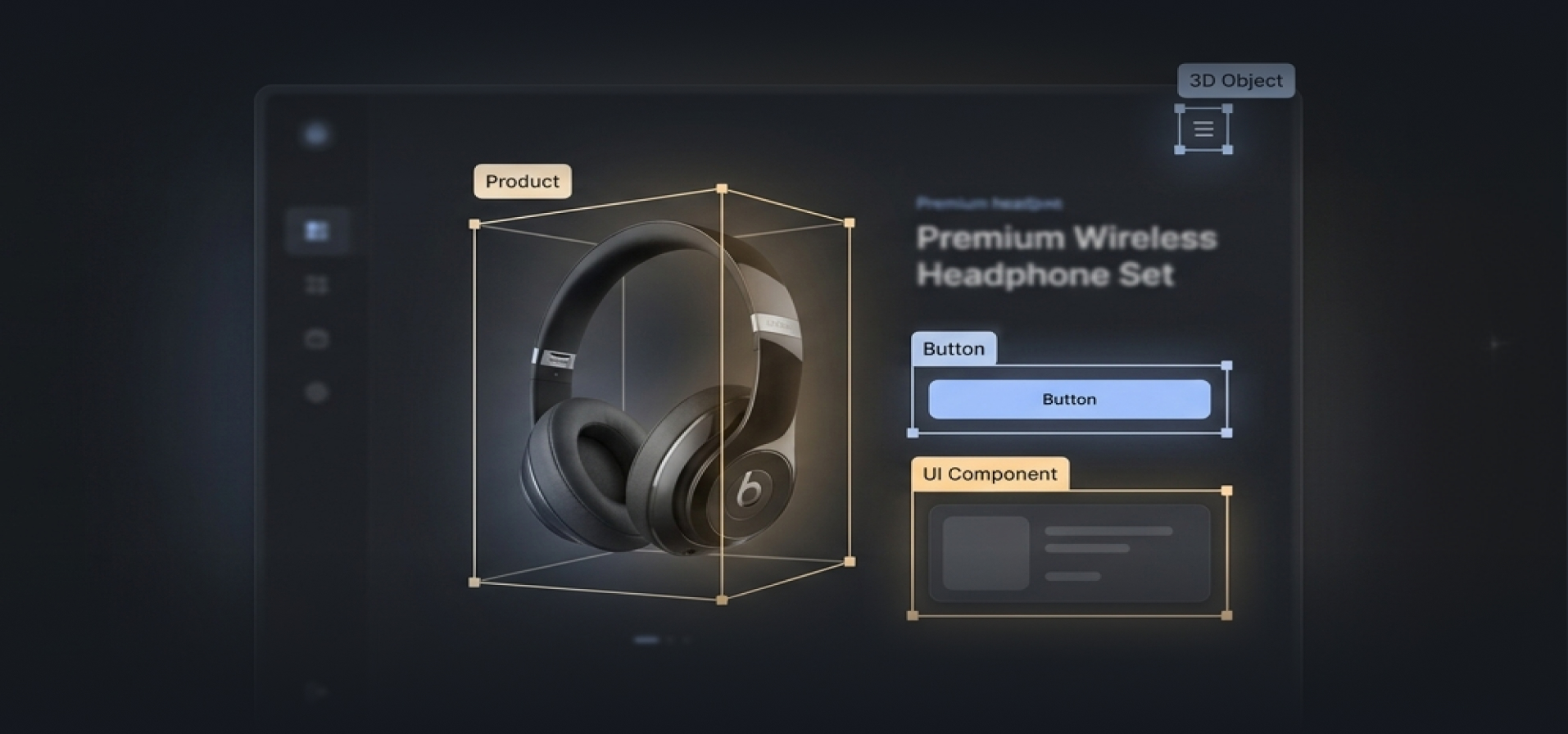
Prepared production-ready training data for a restaurant operations management AI agent through specialized polygon segmentation of food items, enabling multi-chain deployment without client-specific retraining.
20,000+
Annotated Images Delivered98%
Annotation Accuracy Maintained- Service Image Annotation
- Platform CVAT
- Industry F&B (Food Delivery Technology)

Helping an Al-powered astrology app improve palm reading accuracy by 25% through accurate image annotation
25%
Accuracy Boost in Application's Performance10000+
Images Labeled For AI Model's Refinement- Service Image Annotation Polygon & Polyline Annotaton Image Segmentation
- Platform LabelBox
- Industry Astrology