A Complete Video Annotation Guide: Types, Challenges, Opportunities & Much More!
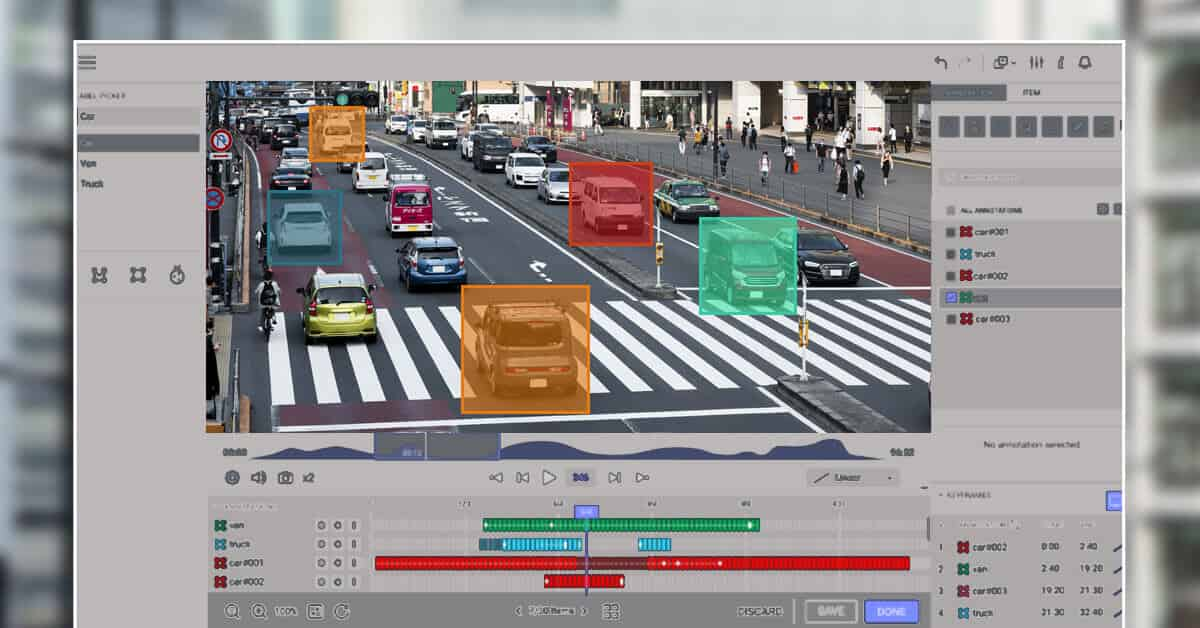
Table of Contents
- Understanding Computer Vision
- What is video annotation?
- What are video annotations used for?
- Other Applications of Video Annotation: Real-life Use Cases
- How does video annotation work?
- 6 Popular Types of Video Annotations & When to Use
- Common Challenges of Video Annotation
- Why Should You Outsource Video Annotation Services?
- Need help with video Annotation?
Artificial Intelligence & Machine learning today has become critical to innovate products, automate even the most complex tasks and uncover new insights. Computer vision is one such application of AI that is transforming industries that generate massive amounts of visual data with the help of video annotation!
Similar to image annotations, video annotation services for computer vision are helping machines to identify or recognize objects through computer vision. Having been said that, video annotation is greatly helping in autonomous vehicles, tracking human activity, facial emotion recognition, and a lot more.
But isn’t this similar to image annotation? Well, yes! But the only difference is, in video annotation, objects are annotated across a series of frames that determine the motion and movement precisely for deep learning applications.
Still not got a fair idea about video annotation & computer vision? Not a problem! Let’s dive into the fundamentals of video annotation.
Understanding Computer Vision
Computer vision is one of the biggest fields of artificial intelligence that allows computers to derive high-level understanding from images, videos, or any other visual input. The applications of computer vision are vast which may vary from facial recognition software to autonomous vehicles, etc.
Since computer vision holds capabilities to surpass human sight, training such models requires abundant annotated pictures or videos.
What is video annotation?
Video annotation is a critical part of machine learning and AI. It is broadly used to label video clips, tag the information inside the video, and thus create training data. This training data is then used to train computer vision models for object identification and detection.
At its core, video annotation and image annotation have very similar processes.
In any video, the entirety is broken down into frames. Then, each frame is treated as a static image, to be annotated accordingly. For instance, take a 100-second long video of 20 fps. By the logic presented, this video becomes a group of 2000 frames, i.e., 2000 static images, where each of which is annotated individually.
What are video annotations used for?
Video annotation can be used for several purposes. However, it is primarily used to create a dataset that can train an AI or ML-based computer model.
During video annotation, a video is broken into frames. We study each structure, detect the objects of interest, classify them, and tag them accordingly. Then, we make this information recognizable to machines so that they can learn to identify those objects with ease without human intervention.
But we can do all of it by using image annotation techniques as well, right?
So, where is the unique use case for video annotation?
Well, in addition to object detection and recognition, video annotation also serves a few other purposes.
- Create precise data variation reports
- Identify the dominant object in any frame (also called object localization)
- Spot the boundaries that separate one thing from another
- Track movement on the screen
- Track human poses and describes perceived intent
Here are a few examples of what video annotation can help you achieve.
In a video of moving traffic, video annotation can help understand where a human ends and a vehicle begins. You can identify which parts of the screen are roads and footpaths or differentiate between vehicle lanes. You can also detect the traffic flow, identify pedestrians, cyclists, road signs, hydrants, crossings, etc.
Or, in any video taken from an Olympic activity, video annotation can help you track human movements, posture, and trajectory. It can later help understand the techniques used by the athletes and improve them further.
Other Applications of Video Annotation: Real-life Use Cases
Other than the above-mentioned uses, we can utilize video annotation tools for various purposes. Some of the most frequent uses of video annotation are mentioned as follows:
- Several video production companies, media firms & designing companies annotate videos so as to identify & highlight odd transitions (if any), spot lightning issues, capture feedback, etc.
- Another prime use of video annotation is in Machine Learning & AI. Also mentioned earlier, data scientists make use of annotation techniques to tag and label videos in order to train machine learning systems to recognize objects in the frames (images) of videos. This could be faces, trees, cars, etc.
- Video annotation is also used by legal departments to annotate video for redaction purposes. This could be censoring the part of a video for security purposes. Some of the common examples include making the faces blur of criminals or discarding any other sensitive clip from a video for eg. CCTV footage that cannot be shown to the public.
- Another important use of video annotation is in the retail sector to identify & track buyers’ behavior at stores. It is also used to detect objects in the frame for eg. price tags, store assistants, shoppers, etc.
- The use of video annotation is also in the healthcare industry. Wondering how? Well, it is used for medical tests such as ultrasound videos to highlight any specific part of the video.
- The use of video annotation is also in the education sector to highlight specific parts of the video to create notes, or also to highlight segments of video that are included in course materials. Furthermore, video annotation tools are utilized to examine students’ learning process & teachers’ teaching delivery process.
- Other than the above-mentioned points, video annotation is widely used for regulatory compliance. This is mainly to ensure that the ads & video content running on television or the internet adhere to mandated guidelines when it reaches the audience.
How does video annotation work?
The frame rate for any video can easily reach 60 FPS. If you sit down to separate that many static images from the video and process each, the entire process becomes unnecessarily complicated. Not to mention, it’ll take longer, cost you more, and exhaust your resources.
Ask annotators or video annotation companies, and they will recount to you the horrors of manual annotation in the face of high data volume.
This is where advanced data annotation tools come into the picture.
Generally, there are two ways to annotate videos quickly and efficiently.
1. Single Frame
The Single Frame or Single Image method is simple and makes sense at face value. Here is what we do:
- Divide the video into as many frames as possible.
- Annotate each frame.
- Assemble the results.
Except, it becomes pretty clear soon enough that this process will warrant more time. And there is a lot of space for inaccuracies.
So, why do we use this method?
When a video has simplified movements, and the objects under consideration are less dynamic in their actions, the number of frames is automatically reduced. That’s where we can use the Single Frame method without losing much time, quality, or effort.
2. Streaming Video
Streaming Video is also called the Continuous Frame method.
- The video runs as a continuous chain of video frames.
- We study each frame as a section of the original narrative and not a standalone frame.
- We can finally annotate the video with appropriate context.
The outcome is more consistent when we annotate videos using the Continuous Video method. In this method, we maintain a transitory state for every object, ensuring that all appearances are recorded in a proper context.
Therefore, the training data thus created is more synchronized and capable of promoting authentic and accurate learning.
By now, you must have a fair idea about the operational workflow of video annotation. At this point, we can conclude that annotating a video is more complex than annotating an image. And yet, both processes serve essential objectives.
Whichever method you choose, keep in mind the importance of synchronization during detection.
For more effective video annotation, service providers often use automation. It helps minimize human intervention while also increasing the speed of the process and creating more accurate results.
6 Popular Types of Video Annotations & When to Use
When looking for video annotation services, you may come across these six popular types of video annotations. Lets quickly get a deeper understanding of each type to help you understand when to use it for your business:
1. 2D bounding boxes
This method involves creating rectangular boxes for object identification, labelling, and categorization. Under this process, annotators need to draw boxes manually around the concerned object. These boxes are drawn during live movement across numerous frames. For getting the most accurate depiction of the object it is important that annotators draw the boxes very close to every edge of the object. Later annotators label the object’s class and characteristics.
When to use this method?
2D bounding boxes are used for object detection & localization like cars, humans, etc.
2. 3D bounding boxes
Similar to 2D bounding boxes, this type of video annotation is applied to get a more realistic 3D depiction of a specific item. With 3D bounding boxes, you get more accurate results as it can also help you know the breadth, length, and depth of the object, even when it is in motion.
When to use this method?
3D bounding boxes too are used for object detection, classification, and localization. However, 3D bounding boxes are more helpful and provide you with a more precise perception of objects, compared to 2D bounding boxes.
3. Splines and lines Annotation
This type of video annotation is widely used in the autonomous driving sector. Under this method, splines and lines are used to let robots identify the borders and lanes. Here, video annotators draw lines between locations which enables AI programs to easily recognize them between frames.
When to use this method?
Other than autonomous vehicles, spines & lines are also used to train warehouse robots so that they can differentiate & recognize different parts of the conveyor belts.
4. Key-points and landmarks
Key points & landmarks are widely used to identify even the tiniest of shapes, postures, or objects. This is because this method involves creating dots all through an image. These dots are then linked to create a skeleton of the object across each frame, key point, and landmark.
When to use this method?
This method is ideal for detecting facial features, human body parts, postures, face recognition, etc.
5. Polygons
Polygons are usually used when 2D or 3D bounding boxes are incapable of correctly depicting an object during its motion. Under this method, annotators create lines by creating and joining dots around the outer border of the object. However, to get the most accurate results, the polygons method requires the annotator’s high level of skills & experience. Hence, it is best to take help from an experienced data annotation company.
When to use this method?
Often, when certain objects do not fit perfectly in a bounding box, using the polygon technique is effective. These are suitable for irregular shapes such as bikes, buildings, houses, etc. within aerial videos.
6. Semantic segmentation
In this method, videos are segmented into components and then later annotated. This requires computer vision experts to carefully examine video frames and classify the objects pixel by pixel.
When to use this method?
This technique can be used for special tasks like anatomy, body part labelling, or when you need to differentiate objects precisely like cyclists, buildings, roads, etc.
Common Challenges of Video Annotation
Video annotation is complex and involves certain challenges such as:
1. Producing plethora of training data:
For computer vision to work accurately, you need to have a large amount of training data. To put it simply, the greater amount of training data you use to develop the model, the more it will predict accurately. And so, this can be quite challenging as you may deal with complex & large volume data. Furthermore, the task becomes even more challenging when objects are constantly in motion in a video.
2. Annotation quality:
Another major challenge involved in video annotation is the quality of annotation. To get the most accurate results, annotators need to pay attention to the entire process. Bad quality or inaccurate annotation can seriously hamper the prediction of the model and will defeat the purpose of annotation. And so, quality & accuracy is given utmost importance to ensure that the training data is of the best quality.
3. Annotation Platform:
Choosing the right annotation software or tool is another challenge faced by annotators. As you may have specific requirements, choosing the best-suited platform that matches your custom requirements is challenging.
4. Choosing the right service provider:
Another challenge is to find a suitable service provider. Since there are a lot of data annotation companies available, picking out the best can be overwhelming. Checking the company’s past experience, previous projects worked on, hiring models, etc is essential before finalizing any video annotation service provider.
5. Automation:
Video annotation is a time taking & complex process. When done manually, it may take a great deal of time, money, and resources. Hence, it is important that you have some level of automation so that you get the most accurate results in a short turnaround time.
Why Should You Outsource Video Annotation Services?
Now that you know what challenges may arise in the video annotation process, the best way to overcome these challenges is to outsource video annotation services. Getting the video annotation done is a difficult task if you don’t have access to the right resources, tools, techniques, and technology. Additionally, this is also a tedious and time-taking process that can take away your precious time & shift your focus from your core business operations. When you hire a video annotation company, it can help you get expert annotators by your side who can work on your project with precision & accuracy.
As there is a huge amount of data required to train computer vision models, it is difficult for in-house teams to scale and provide accurate results. And so, video annotation services outsourcing companies are a popular option for you to quickly get quality services with accurate results.
Other benefits of outsourcing video annotations services are:
- High-quality training datasets: To program the machine right, it is necessary that you have high-quality datasets. Since any mistake in video annotation can result in incorrect results & compromised quality, it is better to leave this work to experts. By simply outsourcing you can have professionals help you attain the highest level of quality & accuracy in data sets.
- Cost-effective solutions: Outsourcing video annotation services can help you save a great deal of money. Since video annotation requires advanced tools & software, and skilled annotators, going for in-house team development can be highly expensive.
- Helps you focus on core business activities: As also mentioned earlier, video annotation is a complex and time taking process that requires full attention. Doing this in-house can take away your valuable time. By outsourcing, you can shift this burden to the experts while you can focus on your core business operations.
- Best techniques & software: A video annotation service provider will come up with the right set of tools and technologies, depending on your project requirements to accomplish your objectives.
- Highly trained resources: To get the desired output, video annotators must be highly trained & skilled. Outsourcing companies have the best resources who are experienced, proficient, and highly trained, to ensure that you give your project in the best hands.
Also read: Why outsourcing video annotation services is profitable to businesses?
Need help with video Annotation?
SunTec India is your best bet when it comes to video annotation services. Providing video annotation services in addition to text annotation, data annotation & image intonation, we have a team of experts who can come up with the best solution to suit your unique business requirements. Right from bounding box to semantic segmentation, polygon annotation, or key-point annotation, our annotators have the skills, technical know-how, expertise, and experience to offer you the best of services!
Still, have more questions about video annotation? Let us know your queries & our team will be happy to assist you!
The SunTec India Blog
Brought to you by the Marketing & Communications Team at SunTec India. We love sharing interesting stories and informed opinions about data, eCommerce, digital marketing and analytics, app development and other technological advancements.