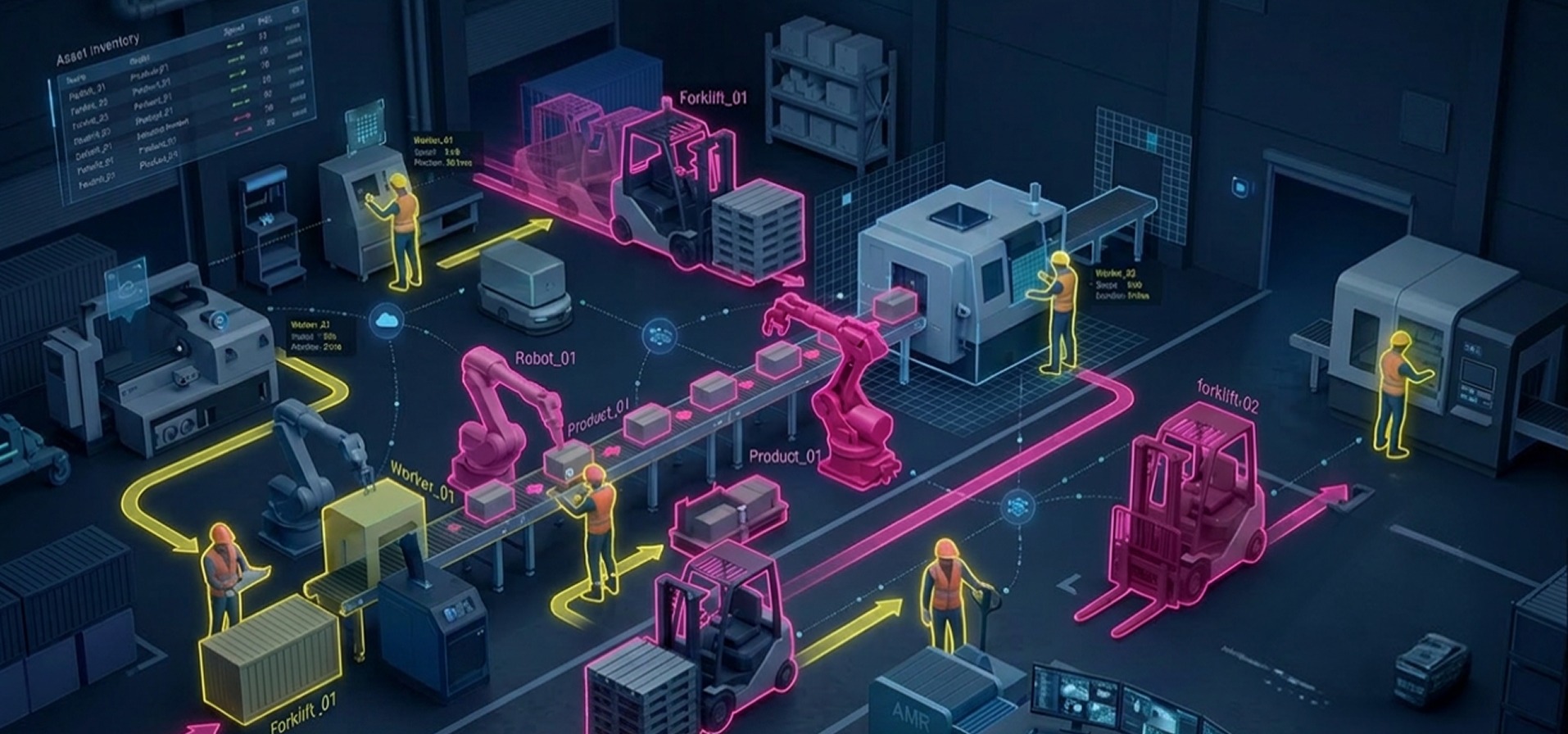
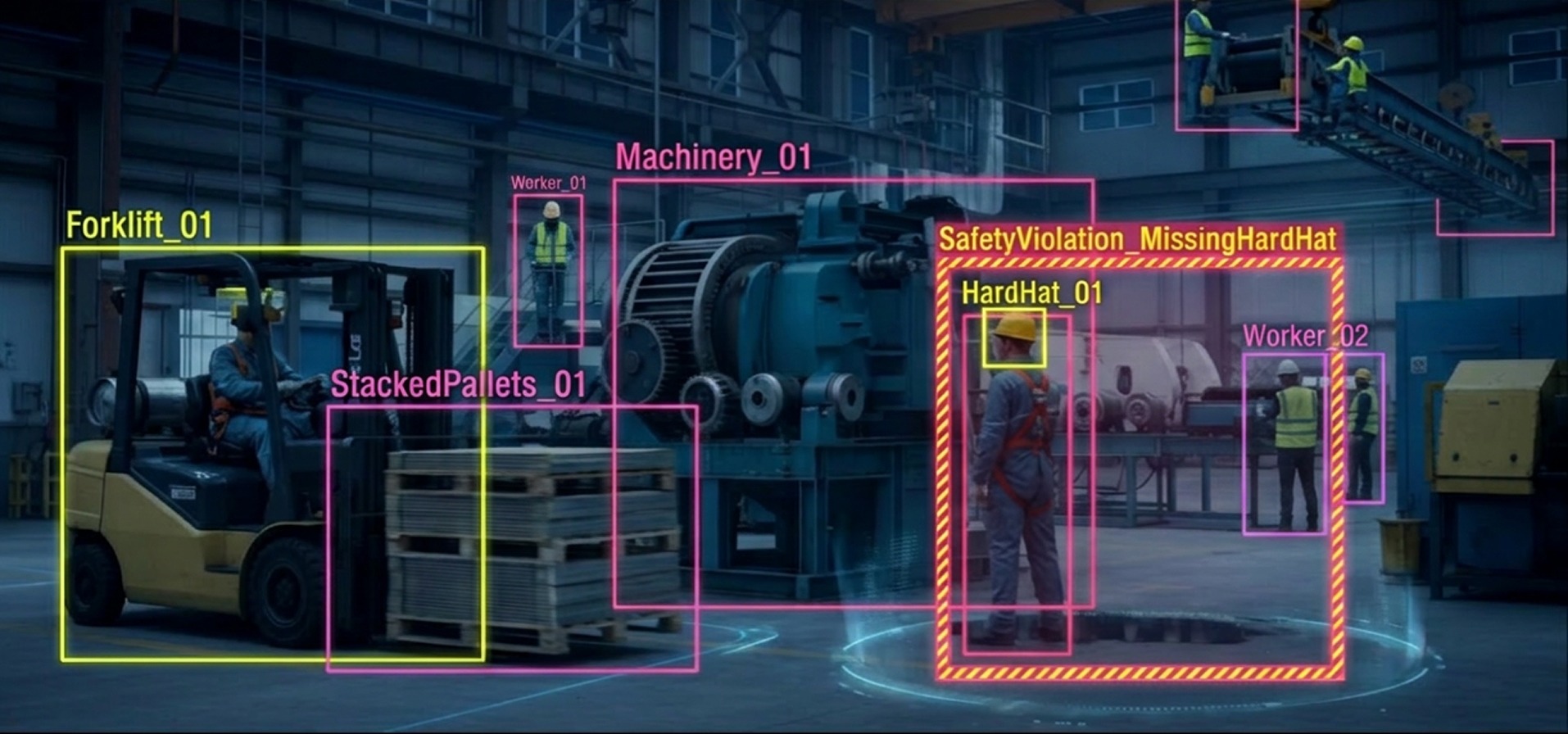
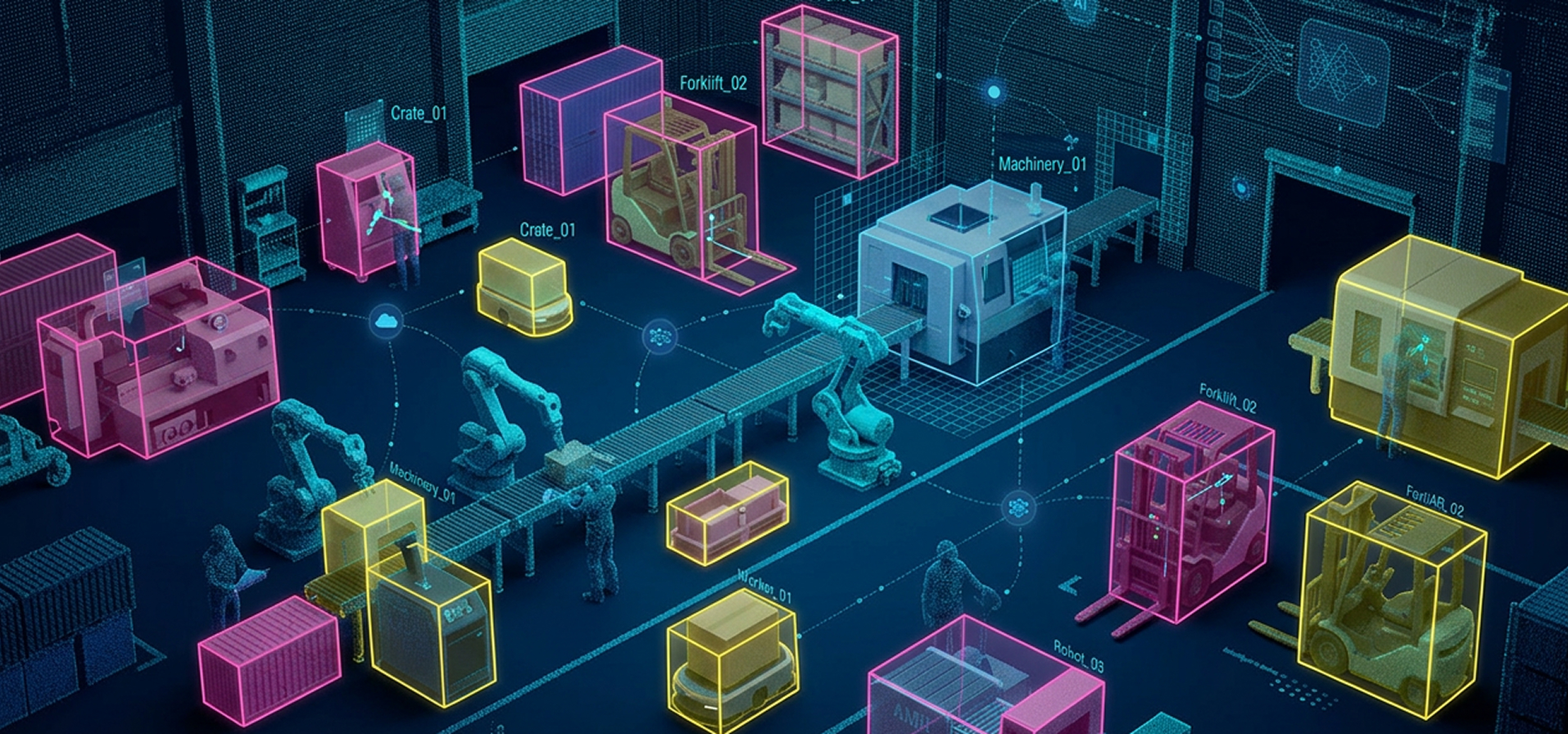
Large-scale image annotation services for a drone-based infrastructure monitoring company developing an automated bird nest detection system on power grids.

15,000+
Images Annotated95%+
Annotation Accuracy- Service Image Annotation Services
- Platform Client’s Proprietary Annotation Platform
- Industry Wildlife Conservation / Energy

Image labeling and training data preparation to power an automated corrosion detection solution for an infrastructure digitization company.
99%
Inter-Annotator Consistency25%
Improvement in Model Precision95%+
Image Labeling Accuracy- Service Image Annotation
- Platform Label Studio
- Industry Telecommunications

Helping a solar panel manufacturer improve the defect detection ability of an AI model by annotating 5000+ images
20%
Reduction in Overhead Costs35%
Increase in Defect Detection Algorithm's AccuracyStreamlined
Solar Panel Maintenance- Service Image annotation Polyline Annotation
- Platform CVAT
- Industry Renewable Energy